

1️⃣ 조건 필터링 나도 해볼래

[ 이것만은 기억!]
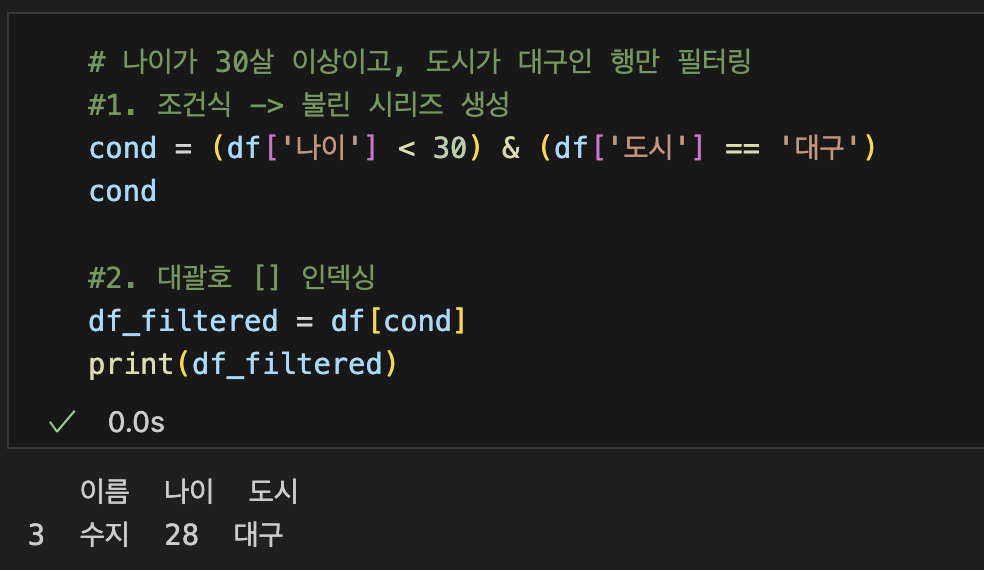
1. 조건식 : 나이 조건(df['나이'] >= 30)으로 불린 Series 생성
2. 대괄호 [ ]로 인덱싱
< 🎯퀴즈 >

#✅ 불린 시리즈 생성
cond = (titanic_df['Survived'] == 1) & (titanic_df['Age'] >= 50)
#✅ 대괄호 인덱싱 : [ ]
survived_50 = titanic_df[cond]
#✅ 원하는 컬럼만 뽑으려면?
result = survived_50[['Pclass', 'Name', 'Sex', 'Age', 'Survived']]
result.head(5)
#✅ 조건에 해당하는 승객 수는?
print("생존한 50세 이상의 승객 수는", len(result),"명 입니다.")
>>> ✍️ 출력:
➡️ 생존한 50세 이상의 승객 수는 27 명 입니다.
#✅ 불린 시리즈 생성
cond = ((titanic_df['Pclass'] == 2) | (titanic_df['Pclass'] == 3)) & (titanic_df['Sex'] == 'male')
#✅ 대괄호 인덱싱 : [ ]
pclas23_male = titanic_df[cond]
#✅ 원하는 컬럼만 뽑고나서
result = pclas23_male[['Pclass', 'Sex', 'Age']]
print(result)
#✅ 조건에 맞는 승객 수는요?
print(f'2등실 또는 3등실 중 남성 승객의 수는 {len(result)}명 입니다.')
>>>✍️ 출력:
➡️ 2등실 또는 3등실 중 남성 승객의 수는 455명 입니다.< 정리 >
▶ 불린 인덱싱(Boolean Indexing):
df[ 조건식 ] 형태로 사용하며, 조건식을 만족(True)하는 행만 선택합니다. 조건식은 ==, !=, >, <, >=, <= 연산자를 사용합니다.
▶ 다중 조건 결합:
여러 조건을 결합할 때는 AND는 &, OR는 |, NOT는 ~를 사용합니다. 각 조건을 반드시 소괄호 ( )로 묶어야 하며, 파이썬의 and/or 키워드는 Pandas에서는 사용할 수 없으니 주의하세요.
▶ 참/거짓 배열 활용:
df['Age'] > 30과 같은 표현은 각 행에 대해 조건을 평가한 불린 배열(Series)을 돌려주며, 이를 다시 df[...]에 사용함으로써 조건을 만족하는 행을 얻습니다.
▶ 주의:
조건 결합 시 괄호를 빼먹거나 and/or를 쓰면 오류가 발생합니다. 또한 df['컬럼'] == 값과 같이 이중 등호(==)를 사용해야 하며, =는 대입으로 쓰이므로 혼동하지 않도록 합니다.
2️⃣ 데이터 정렬 & 정제 어떻게 하는걸까?


< 🎯퀴즈 >

sorted_age = titanic_df.sort_values(by='Age', ascending=False)
sorted_age[['Age', 'Pclass', 'Fare', 'Sex']].head()
#✅ titanic_df 복사
titanic_df_copy = titanic_df.copy()
#✅ Name컬럼(열) 제거
cleaned_titanic = titanic_df_copy.drop(columns='Name')
print("Name컬럼 제거 전:", titanic_df.columns.tolist())
print("Name컬럼 제거 후:", cleaned_titanic.columns.tolist())
#✅ 위 복사본 재사용
#✅ rename 설정: { }
renamed_titanic = titanic_df_copy.rename(columns={'Age':'나이', 'Fare':'요금'})
print("rename전 컬럼 목록:", titanic_df.columns.tolist())
print("rename후 컬럼 목록:", renamed_titanic.columns.tolist())3️⃣ 결측치 처리 꼭 해야 돼?





''' 💡
데이터프레임의 결측치 평균으로 채우기
Age의 평균 : mean_age = df['Age'].mean()
➡️ 수치형 데이터 : df['Age'] = df['Age'].fillna(mean_age)
➡️ 범주형 데이터 : df['Name'] = df['Name'].fillna('Unknown')
'''🧭 결측치 대체 전략 수립
더보기
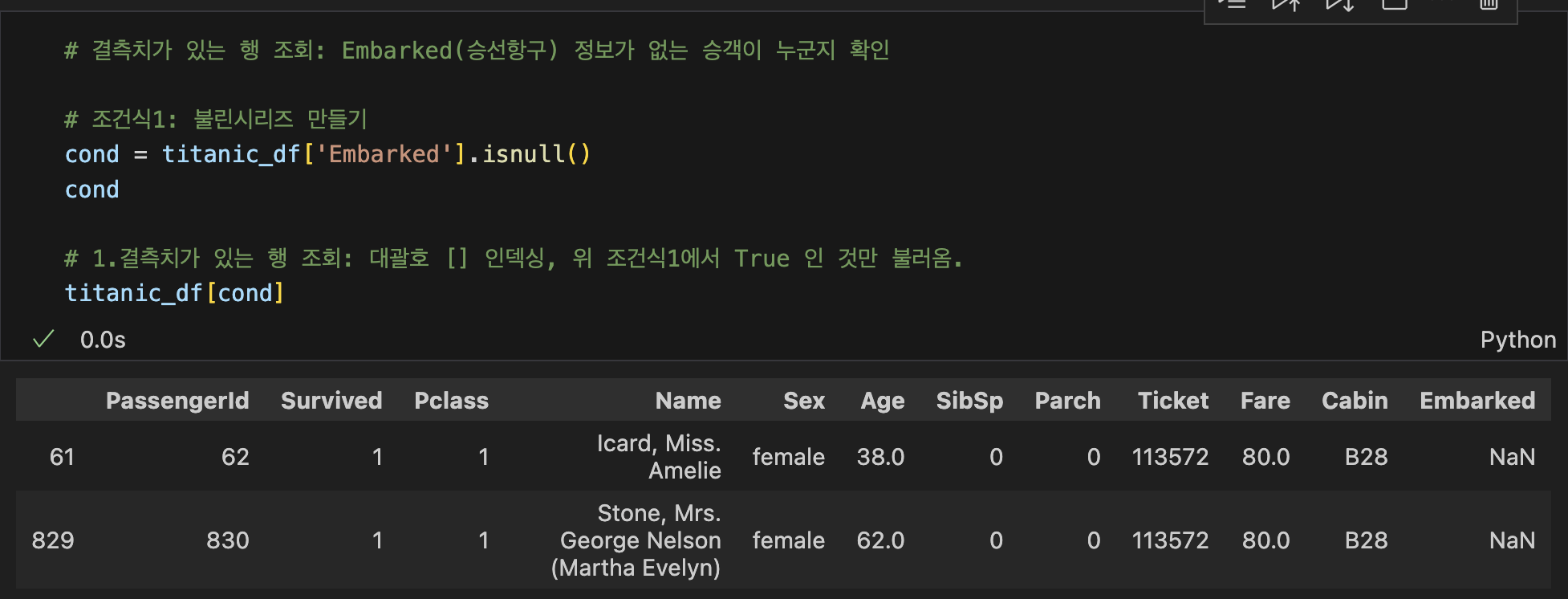
1. df의 결측치와 그 개수 확인 ➡️ df.isnull().sum()
2. 결측치 있는 컬럼: 불린 시리즈 생성 ➡️ cond = df['컬럼명'].isnull()
3. 결측치 있는 행 조회: 대괄호 인덱싱 [ ] ➡️ df[cond]
4. 수치형 데이터 결측: 평균값 / 중앙값 / 최반값 으로 대체
참고) 최빈값으로 대체 시, df['컬럼명'].value_counts() 사용해서 가장 많은 값 확인 후 대체!
< 🎯퀴즈 >

▶ 퀴즈1: Embarked 결측치 처리 (범주형)


▶ 퀴즈2: Age 결측치 처리 (수치형)

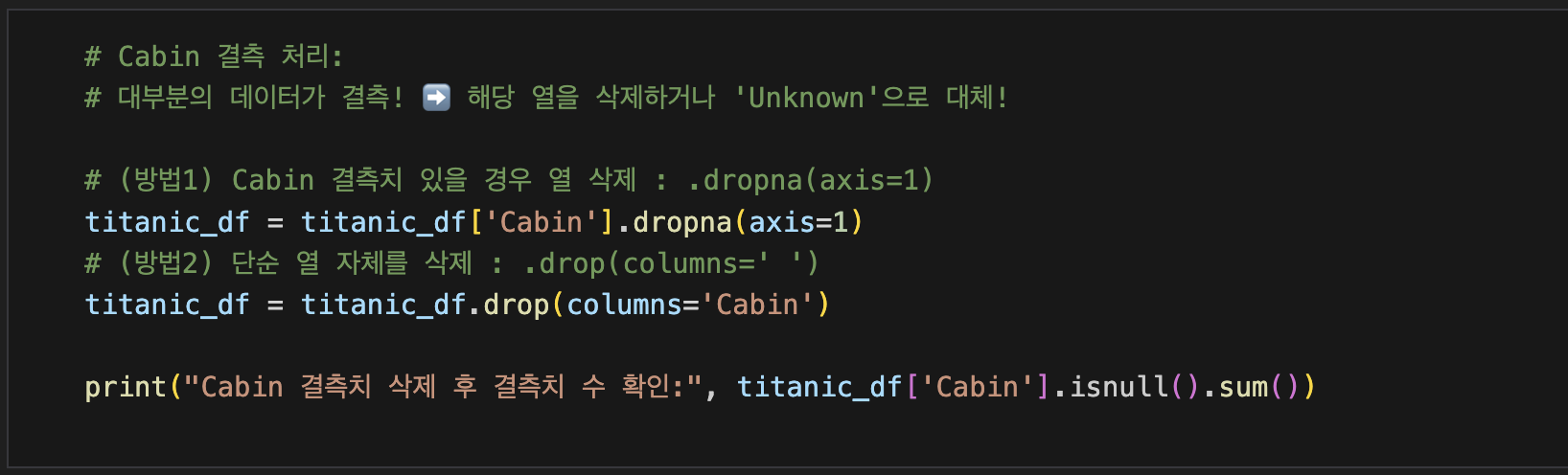
▶ 퀴즈3: Cabin 결측치 처리 (범주형)
4️⃣ 중복 제거는 반드시 해야돼!


titanic_df.duplicated().sum()
titanic_unique_df = titanic_df.drop_duplicates()
print("중복 제거 전 행 개수➡️", len(titanic_df))
print("중복 제거 후 행 개수➡️", len(titanic_unique_df))
>>> ✍️출력:
중복 제거 전 행 개수 ➡️ 891
중복 제거 후 행 개수 ➡️ 891< 🎯퀴즈 >

끝.