

- 기술통계 : 현재의 데이터를 요약하고 설명(기술)하는 통계 - 관찰된 데이터에 집중
- 추론통계 : 일부 데이터(표본)를 바탕으로 전체 모집단을 추정(예측)하거나, 어떤 주장이 맞는지 검정하는 통계
기술 통계(Descriptive Statistics)
현재의 데이터를 요약하고 설명(기술)하는 통계 - 관찰된 데이터에 집중
- 중심 경향치 : 평군, 중앙값, 최빈값
| 개념 | 설명 | 기호 |
| 평균(mean) | 모든 값을 더한 뒤 개수로 나눈 값 | μ |
| 중앙값(median) | 나열했을 때, 가운데 위치한 값 | |
| 최빈값(mode) | 가장 많이 나타나는 값 ➡️ 예: (1, 2, 3, 3, 3, 4, 5, 5) 최빈값: 3 !! |
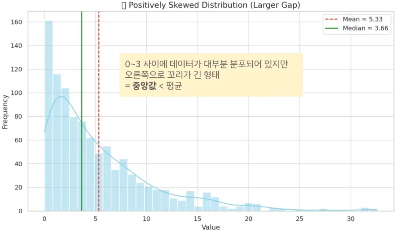
그래프

- 흩어진 정도 : 분산, 표준편차(데이터가 중심에서 얼마나 흩어지고 퍼져 있는지 정도)
| 개념 | 설명 | 기호 |
| 편차(deviation) | 각 데이터가 평균에서 얼마나 떨어져 있는지 | |
| 분산(variance) | 편차를 제곱해서 평균낸 값 | σ² |
| 표준편차(standard deviation) | 분산에 루트를 씌운 값(원래 단위로 복원) | σ |
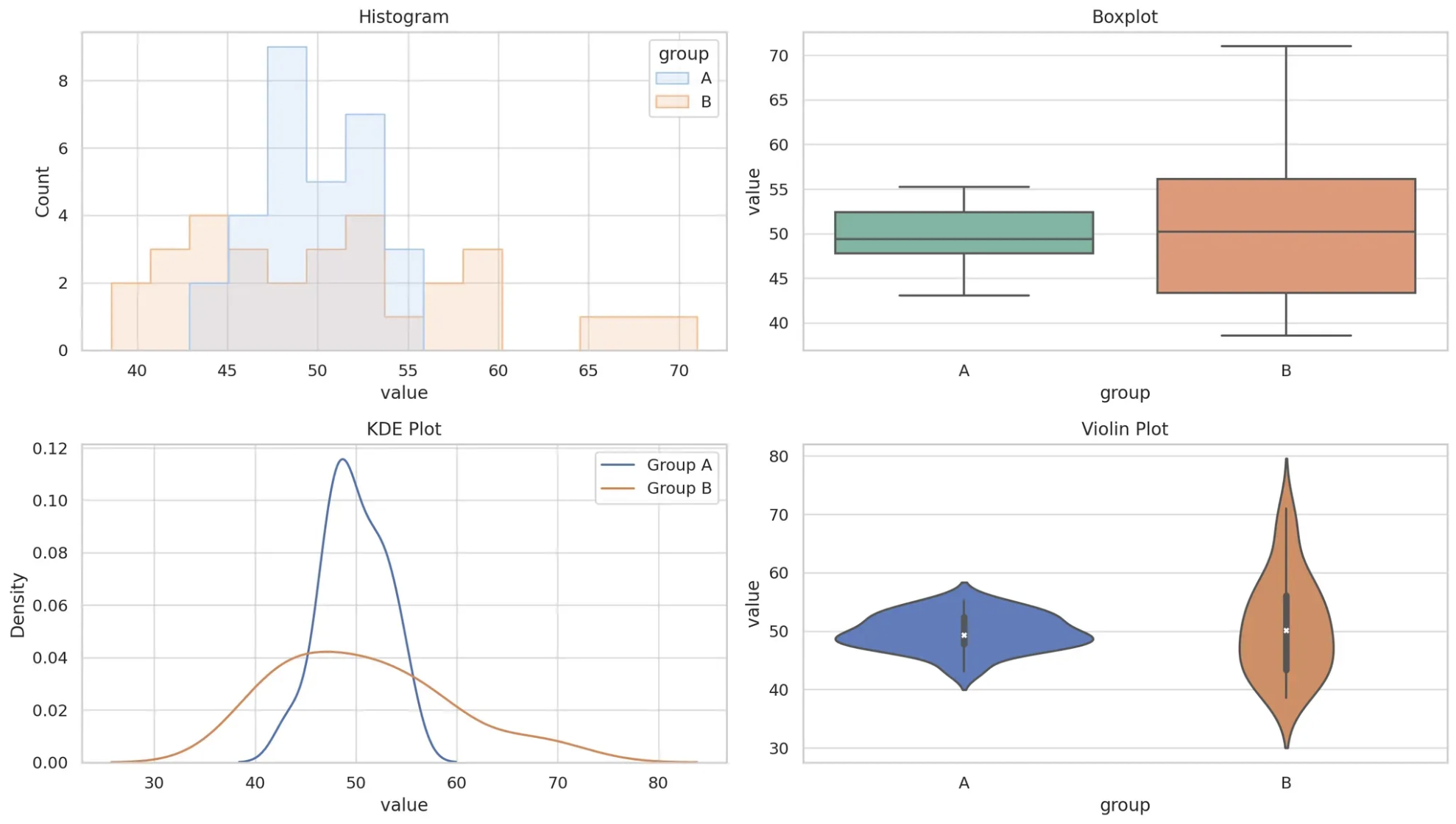
- 분산을 확인할 수 있는 시각화
- 히스토그램, 박스플랏, 밀도곡선, 바이올릿플랏 등
- 분위수( Quantile ) : 데이터를 크기순으로 정렬했을 때, 특정 비율에 해당하는 위치의 값
- 일반적으로 p-분위수는 아래에서부터 p x 100% 위치에 있는 값
| 개념 | 설명 |
| 사분위수 (Quantile) | 데이터를 4등분: - 1사분위수(Q1, 25%) : 하위 25% 지점 값 - 2사분위수(Q2, 50%) : 중앙값(Mendian) - 3사분위수(Q3, 75%) : 상위 25% 지점 값 |
| 백분위수 (Percentiles) | 데이터를 100등분 - 90번째 백분위수(P90) = 전체 데이터 중 90%가 해당값 이하 |
| 십분위수 (Deciles) | 데이터를 10등분 ➡️ 예: 소득분위 (1분위: 하위 10%, 10분위: 상위10%) |
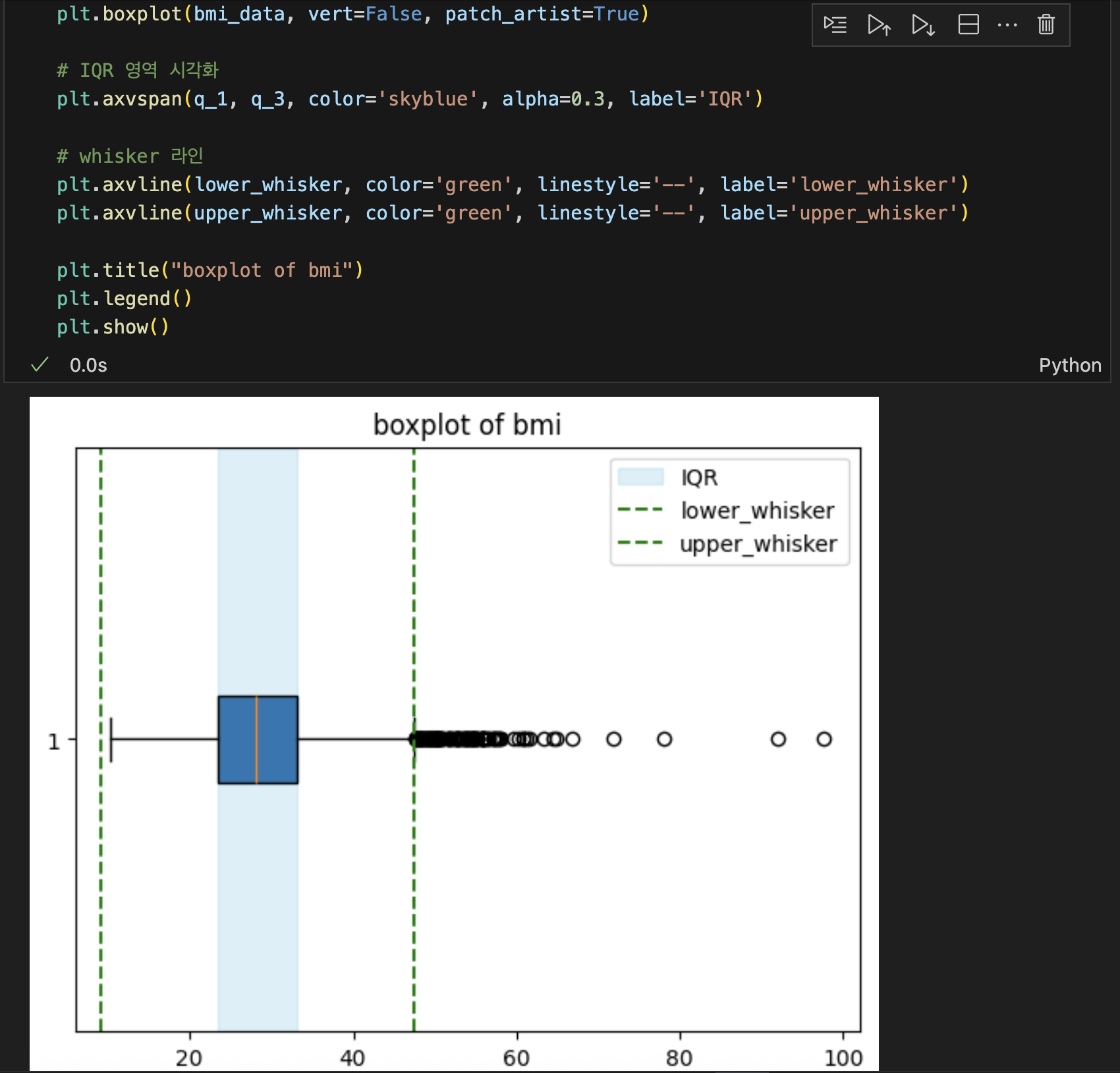
- IQR : Q3 - Q1

- IQR 방식의 이상치 처리
🔥 하단 whisker보다 작거나 상단 whisker보다 큰 값을 제거 !!!
- whisker(하단) : Q1 - ( 1.5 * IQR )
- whisker(상단) : Q3 + ( 1.5 * IQR )
기술통계 실습
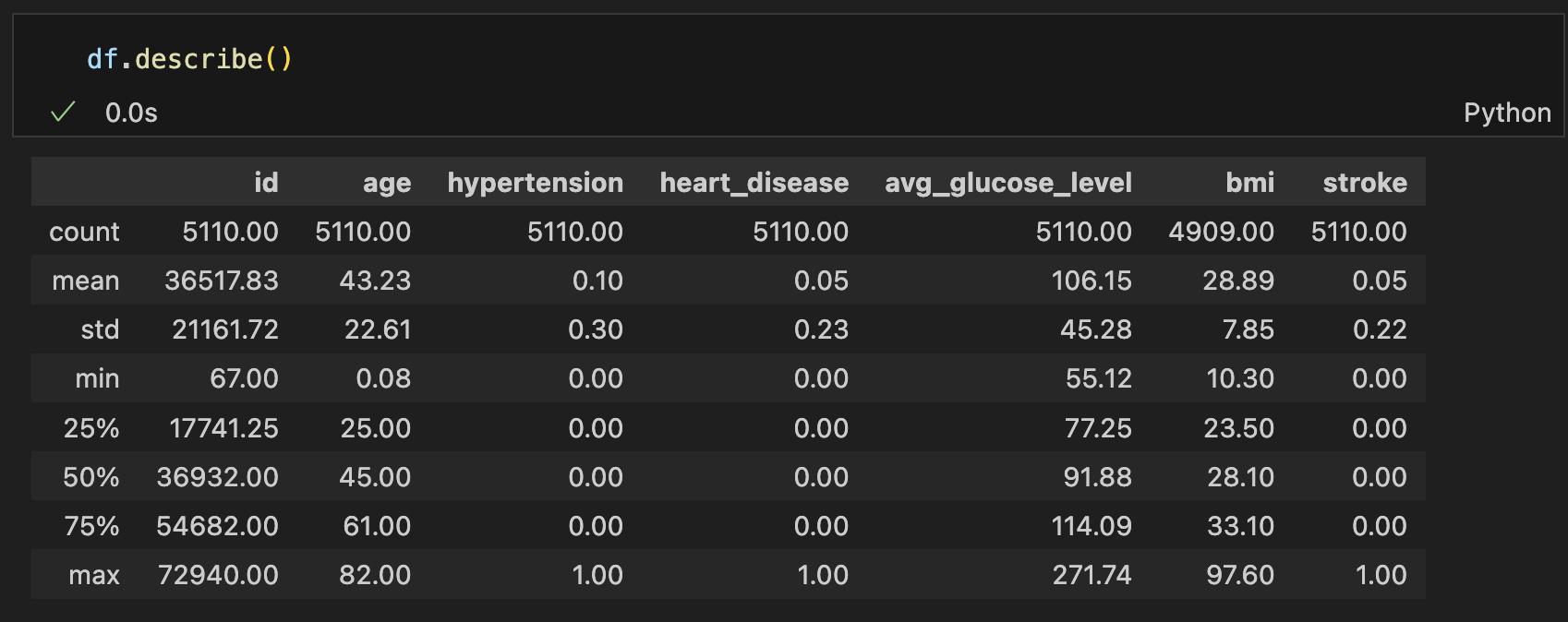
📌 stroke 실습 자료
- describe()로 데이터 요약하기
- 히스토그램으로 데이터 분포 시각화
- IQR 방식으로 이상치 제거
- boxplot 그리기



추론 통계 (Inferential Statistics)
일부 데이터(표본)를 바탕으로 전체 모집단을 추정(예측)하거나, 어떤 주장이 맞는지 검정하는 통계
- 기술 통계는 '있는 데이터를 요약'하고, 추론 통계는 '없는 모집단을 예측'한다는 차이! (ex. 여론조사)
- 모집단은 전부 관측할 수 없어서 표본을 추출하지만 이 표본이 얼마나 신뢰할 수 있는 정보인지 추정해야 함

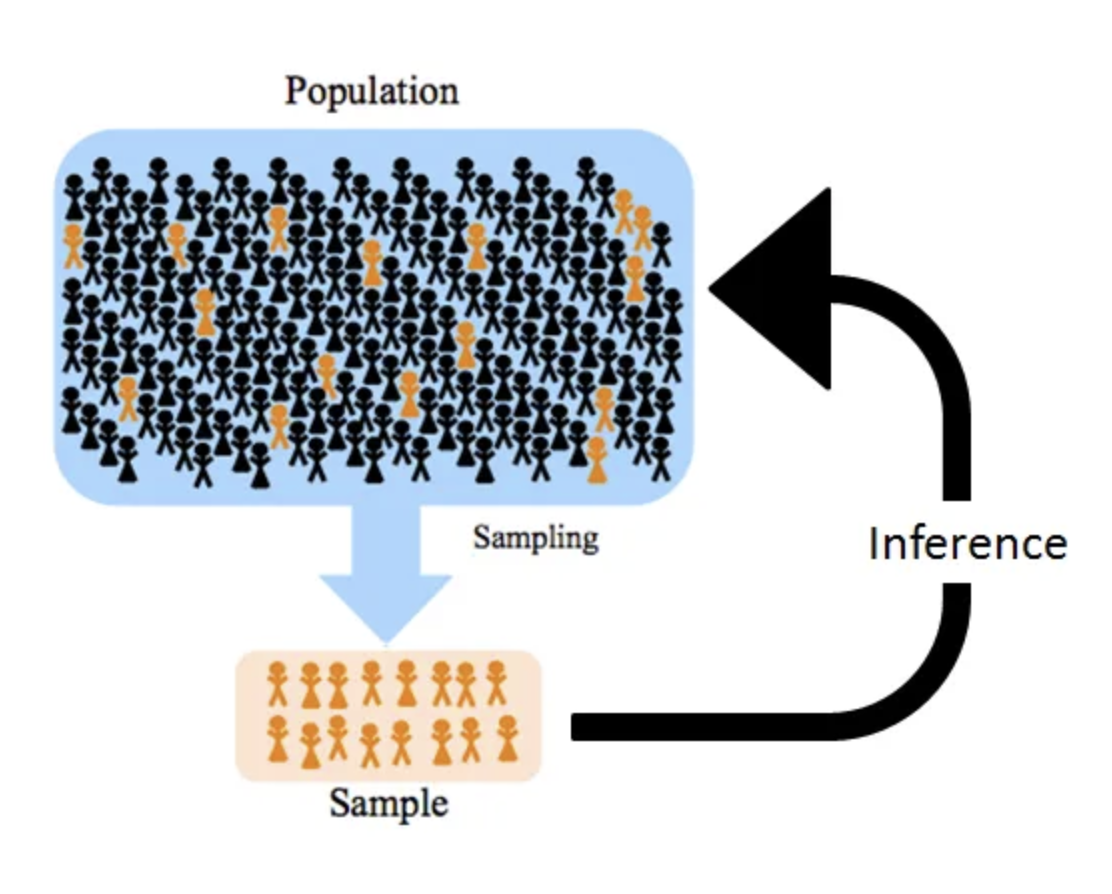
추정과 가설검정
- 추정 (Estimation)
- 모집단의 평균, 비율 등은 알 수 없기에 '표본'을 통해 '추정'
- 값을 추정하거나 구간을 추정할 수 있음
| 개념 | 설명 | 예시 |
| 점추정 | 하나의 숫자로 모수 추정 | 모집단 평균은 약 65다 |
| 구간 추정 | 신뢰 가능한 범위를 제시 (= 신뢰구간) | 모집단의 평균은 62-68 사이일 것이다 |
- 가설검정 (Hypothesis Testing)
- 어떤 주장이 우연인지, 우연이 아닌지 확인하는 과정
- 우연이 아니다 = 통계적으로 유의미하다.
- 어떤 주장이 우연인지, 우연이 아닌지 확인하는 과정
모집단과 표본
✅ [ Key point ] 모집단을 추정한다 = 표본을 통해 모집단의 특성(평균/분산)을 추정한다.
- 표본평균과 표본분산
- 모집단과 표본이 차이가 날텐데? ➡️ 표본오차 (sampling error)
- 어떻게 추정이 가능할 수 있는거야? ➡️ 중심극한정리 !
모집단의 특성을 알아보자!
표본의 평균과 분산
- 우리는 표본의 평균(\bar{X})과 분산(s^2)으로 모집단의 평균과 분산을 추정할 수 있다.
- why? 중심극한정리


표본오차 (Sampling Error)
- : 표본평균(\bar{x}) - 모집단평균(μ)
- → 우리가 측정한 값과 실제 값(모집단)의 차이
- 표본을 무작위로 뽑는 과정에서 표본마다 평균이 다를 것이다. => 즉, 표본오차도 달라진다.
- 그렇다면 표본으로 모집단의 평균(\mu)을 어떻게 알 수 있지?
- why? 큰 수의 법칙 (Law of large numbers)

표준오차 (Standard Error)
- : sampling error 의 표준편차 = 표본평균의 표준편차
- 중심극한 정리에 따르면, sampling error의 분산은 \frac{\sigma^2}{n}이다.
- 하지만 우리는 모집단의 분산($\sigma^2$)을 모르니까 우리가 아는 표본의 분산($s^2$)으로 대체한다 → $\frac{s^2}{n}$
추론통계 실습
✅ stroke 실습자료
- df.sample() 로 데이터 샘플링하기
- 샘플의 평균과 분산 구해서 전체 데이터와 비교하기
- 중심극한 정리
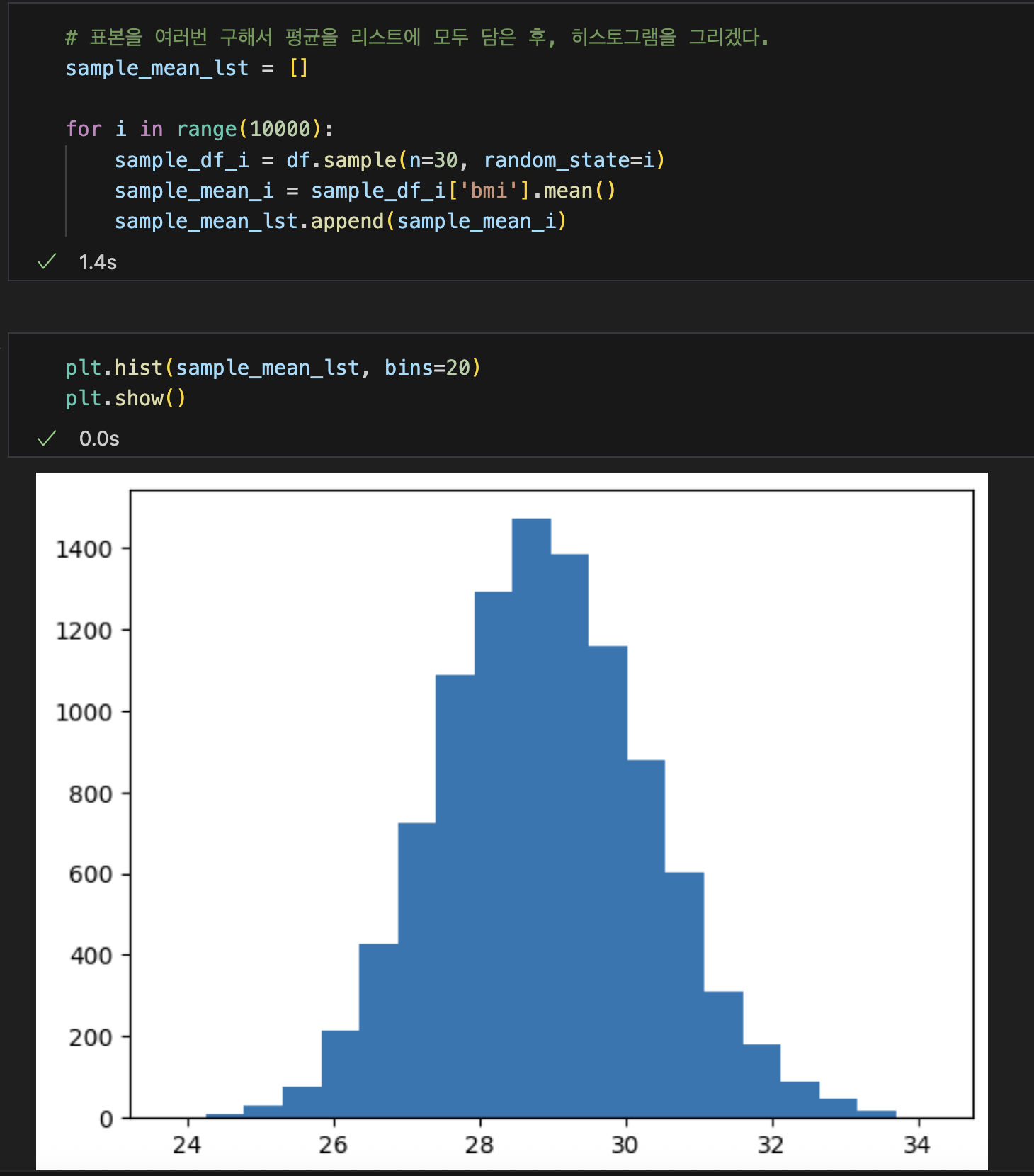
- 샘플 여러개를 구해서 표본평균의 히스토그램 그려보기



궁금증
더보기



- sample_df = df.sample(n=30, random_state=1) 에서 random_state는 어떤 기능이야?
- 랜덤으로 평균을 구한다고 가정할 때, random_state를 특정값(아무값)으로 설정하면 항상 동일한 결과(평균)을 얻게 됨.
- np.mean(..) 평균 | np.std(..) 표준편차 | np.var(..) 분산 | np.power(** , 2) **를 제곱, 3이면 세제곱
- 표본평균의 분산 = 표준오차의 제곱
- 표준편차 vs 표준오차
끝.
🔍 중심극한정리에 대한 오해와 진실
[중심극한정리에 대한 오해가 있을 수 있어 아래 내용 참고해주세요.]
더보기
중심극한정리: 모집단에서 크기가 n인 표본을 뽑아 평균을 구하는 과정을 반복하면, 이 표본평균들의 분포는 n이 충분히 클 때 정규분포에 가까워진다.
중심극한정리가 왜 중요할까요?
• 모집단이 어떤 분포든 표본평균으로 모집단의 평균에 대해 추론이 가능합니다!
핵심 포인트
1. 무엇이 정규분포가 되는가?
• 개별 데이터는 정규 분포를 따르지 않습니다.
• 표본평균들의 분포가 정규 분포를 따르게 됩니다.
2. 필수 조건
• 표본들이 서로 독립적 (표본들끼리 서로 영향을 안줌)
• 모집단의 평균과 분산이 유한
• 표본 크기(n)가 충분히 큼
예시로 이해하기
• 주사위 던지기
• 주사위 1개의 분포: 1,2,3,4,5,6이 균등하게 나옴 (정규분포 아님)
• 주사위 30개의 평균의 분포: 대부분 3~4 사이에 몰림 (정규분포에 가까움)
• 주사위 100개의 평균의 분포: 거의 항상 3.5 근처 (더욱 정규분포에 가까움)
오해할만한 사항
❌ 오해 1: "개별 데이터가 정규분포를 따른다"
✅ 진실: 개별 데이터는 그대로. 평균의 분포만 정규분포가 됨
• 예: 주사위를 아무리 많이 던져도 1~6이 균등하게 나옴. 하지만 30개씩 평균을 내면 그 평균들이 종 모양을 그림
❌ 오해 2: "많이 반복 하면 정규분포가 된다"
✅ 진실: 표본 크기(n)가 클수록 정규분포에 가까워짐. 반복 횟수는 분포 모양을 바꾸지 않음
• 10명 평균 × 10,000번 = 여전히 덜 정규분포적
• 100명 평균 × 100번 = 이미 정규분포에 가까움
❌ 오해 3: "모든 통계량이 정규분포를 따른다"
✅ 진실: 평균(또는 합계)에만 적용
❌ 오해 4: "표본의 크기가 30개면 무조건 충분하다"
✅ 진실: 30은 경험적 기준일 뿐. 개별 데이터의 분포에 따라 다름
• 대칭 분포: 20~30개도 괜찮음
• 심하게 치우친 분포(소득): 100개 이상 필요
• 극단값이 많은 분포: 수백 개 필요할 수도 있음
기술통계 추론통계 관련용어 정리표 (gpt 발췌)
| 항목 | 기술통계 (Descriptive) | 추론통계 (Inferential) | 핵심 질문 | 권장 시각화 / 예 |
| 목적 | 관측된 데이터셋을 요약·제시 (무엇이 관측되었나). |
표본을 이용해 모집단에 대한 추정·검정 (표본 → 모집단). | “이 데이터는 어떠한가?” / “모집단에 일반화할 수 있나?” | 히스토그램, 박스플롯, 빈도표 |
| 대상 | 주어진 데이터(표본 또는 전체). | 표본을 통해 모집단(parameter)을 추정하거나 가설 검증. | — | — |
| 주요 용어 | 평균(mean), 중앙값(median), 최빈값(mode), 분산(var), 표준편차(sd), 사분위수(IQR) |
모수(parameter), 통계량(statistic), 표준오차(SE), 신뢰구간(CI), p-value, 검정통계량 | “중심과 변동성은?” / “추정값은 얼마나 신뢰할 수?” | 요약표(요약 통계량) |
| 중심경향성 | 평균, 중앙값, 최빈값 — 데이터의 중심을 표현 |
표본평균 xˉ\bar{x}으로 모집단 평균 μ\mu 추정 (점추정) | “중심은 어디인가?” | 히스토그램 + 세로선(평균/중앙값) |
| 산포 (변동성) |
분산 s2s^2, 표준편차 ss, IQR — 데이터 퍼짐 |
표준오차 SE=s/nSE = s/\sqrt{n}로 추정 불확실성 측정 | “측정값들이 얼마나 흩어져 있나?” | 박스플롯, 산점도 |
| 표본분포 / 중심극한정리 |
(기술적 설명은 제한적) | 표본평균의 분포가 nn이 크면 정규에 근접 — 표본분포 기반으로 CI·검정 수행 | “평균의 분포는 어떤가?” | 표본평균의 분포 개념도 |
| 신뢰구간 (CI) |
(요약값 제공) | 점추정 ± 임계값×SE. 예: xˉ±z0.975×SE \bar{x} \pm z_{0.975}\times SE 또는 tt 사용 | “모집단값이 어느 범위에 있을까?” | 점추정과 오차막대(에러바) |
| 가설검정 (Hypothesis test) |
(없음 — 대신 기술적 비교는 가능) | 귀무가설H0H_0과 대립가설H1H_1 설정 → 검정통계량 → p-value로 판단 | “데이터가 우연에 의한 결과인가?” | t-분포/카이제곱 분포 등 시각화 |
| p-value의 의미 | — | 귀무가설 하에서 관측값 이상 극단적 값이 나타날 확률 | “이 관측은 우연히 나올 수 있는가?” | 검정통계량 위치 표시 |
| 오류와 검정력 | — | Type I(α: 거짓 양성), Type II(β: 거짓 음성), 검정력 = 1−β1-β | “오류 가능성은 얼마인가?” | 표본크기·효과크기 시나리오 표 |
| 가정 (Assumptions) |
없음(단, 요약 해석 시 분포·이상치 고려) | 각 검정별 가정(정규성, 등분산성, 독립성 등). 위반 시 비모수 대안 필요 | “가정이 충족되나?” | Q-Q 플롯, 잔차분석 |
| 실무적 사용 기준 | 데이터 설명·보고·EDA (탐색적 데이터분석)에 사용 |
의사결정·과학적 결론·정책 제안 등에 사용(표본 통해 모집단 결론) | — | 요약 보고서, 신뢰구간 표기 |
📖 내용과 연계하여 읽어보면 좋을 아티클
https://yozm.wishket.com/magazine/detail/1644/
A/B 테스트 제대로 이해하기: 2A/B 테스트를 위한 기초 통계 이해하기 | 요즘IT
앞선 글에서 A/B 테스트를 설계하거나 수행할 때 ‘목표를 달성하기 위한 방안으로 A와 B 중 어느 게 더 나은가?’ 뒤에 숨은 진짜 질문에 관해 살펴보았다. 이번 글에서는 이러한 우리의 진짜 질
yozm.wishket.com
끝.