

🔍 표본오차와 신뢰구간
1) 표본오차 (Sampling Error) : 표본에서 계산된 통계량과 모집단의 진짜 값의 차이
- 표본 크기가 크다 ➡️ 표본오차 작아짐
- 표본이 완벽하게 대표하지 못하기에 발생
- 표본의 크기 : 표본의 크기가 클수록 줄어듦. 데이터를 많이 수집!
- 표본 추출 방법 : 무작위 추출 방법, 모든 요소가 선택될 동등한 기회가 되어야함!
2) 신뢰구간 (Confidence Interval) : 모집단의 특정 파라미터(평균, 비율)에 대해 추정된 값이 포함될 것으로 기대되는 범위
- 일반적으로 95%의 신뢰구간을 많이 사용 ( 95% 일 때, z = 1.96)
- 신뢰구간 = 표본평균 ± z × 표준오차
3) 표본오차, 신뢰구간 그림으로 확인
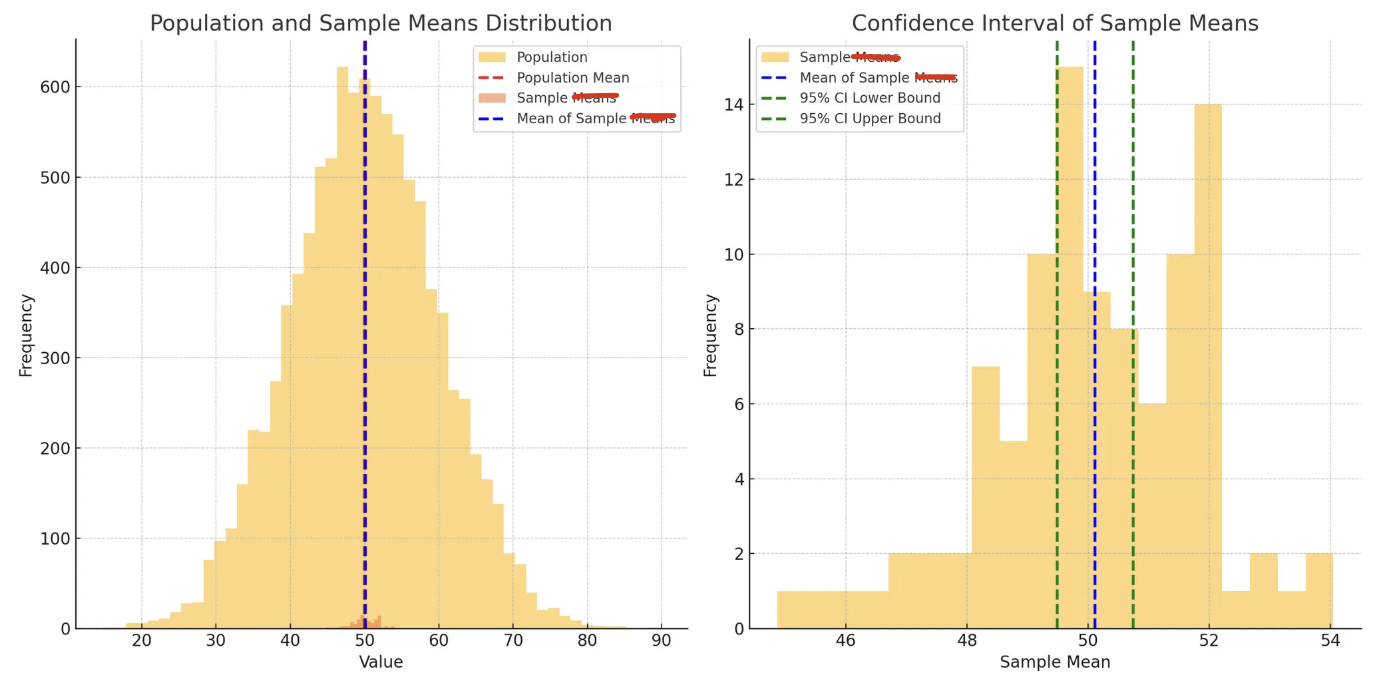
▶ 표본오차와 신뢰구간 : 실제로 어떻게 사용될까?
1) 수학점수 표본으로부터 모집단의 평균 범위를 계산해보자
- 100명의 학생 표본 추출
- CH1에서 실습했던 sample을 가져와 표본 평균 & 이 점수의 신뢰구간 계산
import scipy.stats as stats
# 표본 평균과 표본 표준편차 계산
sample_mean = np.mean(sample)
sample_std = np.std(sample)
# 95% 신뢰구간 계산
conf_interval = stats.t.interval(0.95, len(sample)-1, loc=sample_mean, scale=sample_std/np.sqrt(len(sample)))
print(f"표본 평균: {sample_mean}")
print(f"95% 신뢰구간: {conf_interval}")[ 🤔stats.interval 이란 무엇일까? ]
scipy.stats 는 SciPy 라이브러리 일부 | 통계 분석을 위한 다양한 함수와 클래스 제공
scipy.stats.t.interval 함수는 주어진 신뢰 수준에서 t-분포(밑에서 얘기하는 student t 분포)를 사용하여 신뢰 구간 계산에 사용
scipy.stats.t.interval(alpha, df, loc=0, scale=1)
- alpha : 신뢰 수준을 의미. | 예: 95% 신뢰 구간을 원하면 alpha=0.95로 설정
- df : 자유도(degrees of freedom) | 일반적으로 "표본 크기 -1"로 설정
- loc : 위치(parameter of location) | 일반적으로 "표본 평균"을 설정
- scale : 스케일(parameter of scale) | 일반적으로 표본 표준 오차(standard error)를 설정 | 표본 표준 오차는 표본 표준편차를 표본의 크기의 제곱근으로 나눈 값 (scale = sample_std / sqrt(n) )
끝.
'통계 (Statistics)' 카테고리의 다른 글
| [통계/인강] 챕터2(3) - 정규분포 & 긴꼬리 분포 & 스튜던트 t 분포 (0) | 2025.09.22 |
|---|---|
| [통계/인강] 챕터2(1) : 모집단과 표본 | plt.hist( ) | np.random.normal( ) | np.random.choice( ) (0) | 2025.09.22 |
| [통계/인강] 챕터1 - 통계 중요성 & 기술통계/추론통계 & 다양한 분석방법 (1) | 2025.09.18 |