

[세션] 분석적 사고력 훈련 5회차 - 현업의 ML 모델링 방법
4회차 요약
성공적인 보고의 3단계 흐름 : 결론 -> 핵심근거 -> 분석 증명
실무의 냉혹한 현실
데이터셋을 받으면 바로 model.fit() 하면 끝? Never !!
- 실제 데이터는 깨끗하지 않음
- -> 직접 분석 가능한 데이터셋을 만들어야 함
- Y값(정답지)은 존재하지 않음
- -> LTV나 Fraud 같은 Y값은 사전에 존재하지 않음 -> 직접 정의하고 가공해야 함
- 리소스는 유한함
- -> ML모델링 업무에 대한 우선순위를 비즈니스 가치로 증명해야 함
3가지 case study를 통한 ML 실무 학습
[case1] 고객 LifeTime Value(LTV) 예측
PM의 요청: "마케팅 비용을 효율화하고 싶어요. 신규 유저의 LTV를 예측해서 가치 있는 유저에게만 광고비를 집중하고 싶어요."
* LTV(고객 생애 가치) : 고객 한 명이 우리 회사에 가져다줄 총 가치
TIP1. 장기 예측값을 단기 변수로 예측
핵심 분석 과제:
- Y(예측값): LTV는 1년 뒤에나 알 수 있는 '장기적인' 지표
- X(단서): 우리는 고객이 가입한 첫날의 '단기적인' 정보만 사용해야 함
!! ML의 역할 : 1년 뒤를 기다리지 않고 고객의 단기 피처(X, 첫날 방문 빈도)를 사용해, 장기 예측값(Y, 1년 뒤 수익)를 미리 예측
TIP2. 예측에 맞는 데이터셋 설계
1. Y값(정답지) 만들기
- 먼저 현설적인 Y값 정의 (LTV = 고객 가입 후 1년 이내 총 수익)
- 학습 데이터를 만들기 위해 "1년 전 (2024년 11월)에 가입한 고객들"을 모두 불러오고, 2025년 10월까지의 총 구매액(LTV)"을 Y값으로 확정
2. X값(단서) 만들기
'가입 첫날' 데이터만 추출
- 유입 경로
- 사용 기기 / OS
- 지역 / 언어
[case2] 사기 감지 (Fraud Detection)
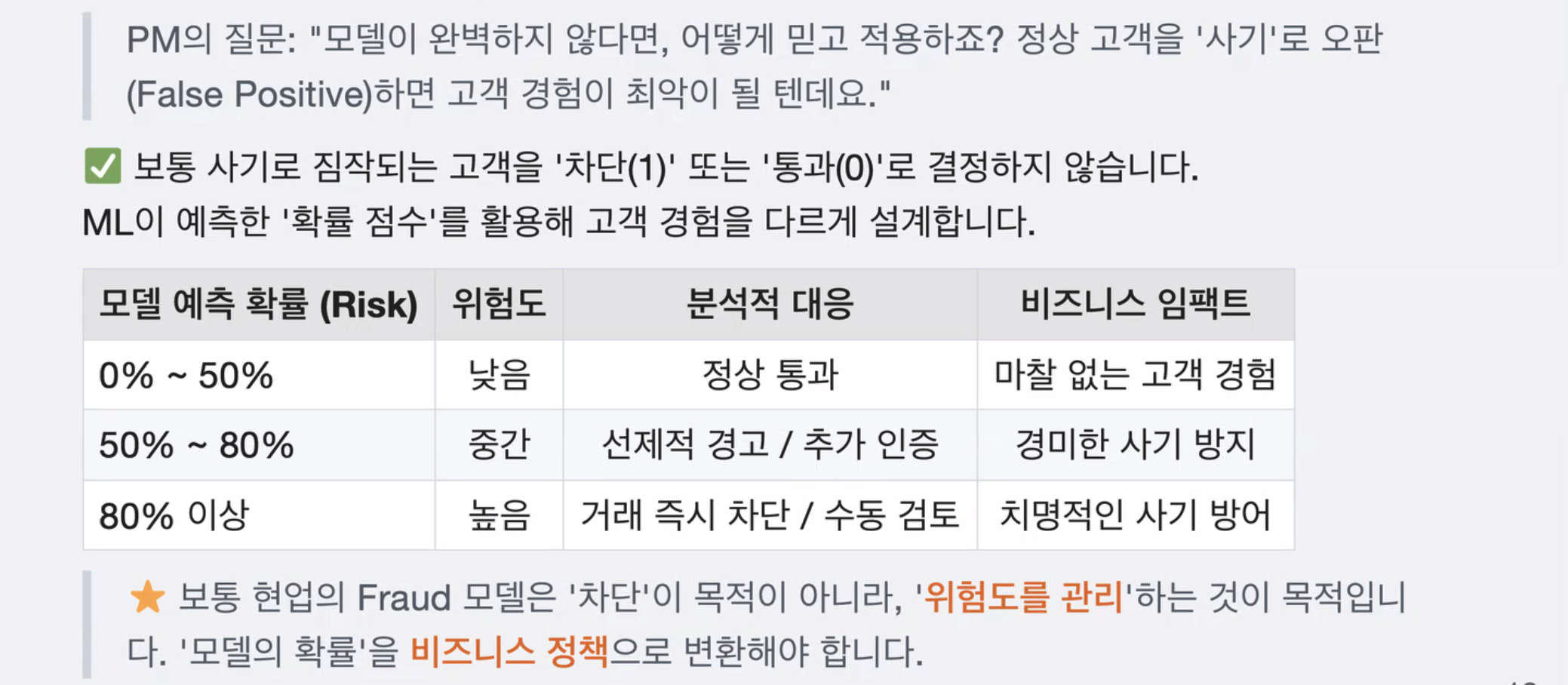
학생: "사기 예측 모델을 만들었어요. 제 노트북에서 정확도가 99%가 나왔습니다. 완벽합니다."
현업 분석가 : "이 모델은 쓸 수 없어요. 데이터 불균형에 빠졌을 가능성이 높다.
TIP1. '정확도'의 함정(불균형 데이터)

TIP2. Data Leakage 조심하기

TIP3. '위험도'에 따른 차등 정책
[case3] 개인화 (personalization)
"Y값이 있는데 어떻게 개인화에 써야 할까?"
PM의 요청 : "이메일 마케팅 효율이 떨어집니다. 짤은 이메일이 좋은지, 긴 이메일이 좋은지 모르겠어요. 고객별로 최적의 이메일을 보내고 싶어요"
Y값 정의: Y = 이메일 클릭 여부
기존 클릭률 : 2%
TIP1. '평균 최적' vs '개인 최적'

TIP2. '개인 최적화'를 위한 X값(피처) 설계

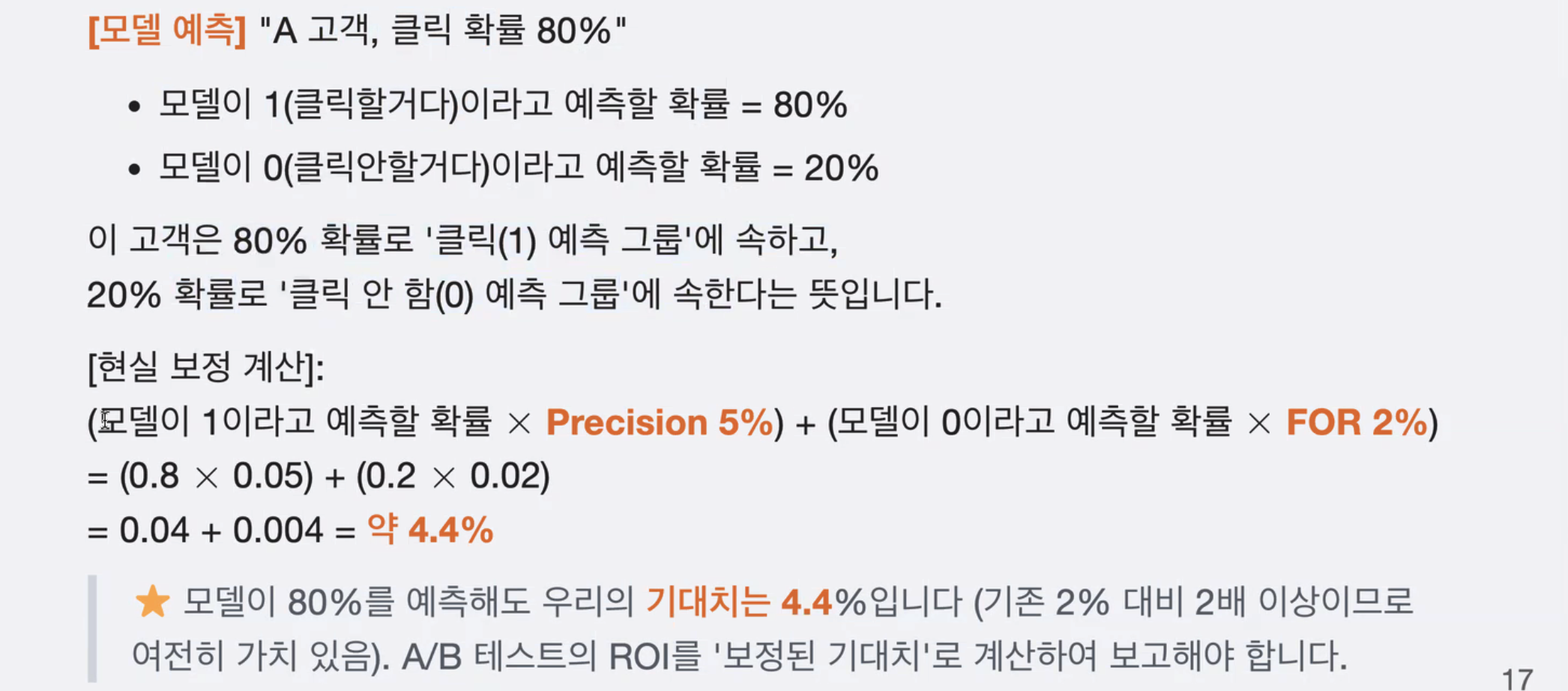
TIP3. 모델 예측의 '현실 보정'

'내일배움캠프' 카테고리의 다른 글
| [세션] 데이터로 설득하는 시각화의 기술 5회차 - 스토리텔링 (0) | 2025.11.24 |
|---|---|
| [세션] 데이터로 설득하는 시각화 기술 4회차 (0) | 2025.11.21 |
| [세션] 분석적 사고력 훈련 4회차 - 결과를 설명하는 방법(스토리텔링, 청중의 입장) (0) | 2025.11.21 |