

필요한 라이브러리 임포트
import numpy as np
import pandas as pd
# 스케일링, 폴리노미얼, 라벨인코딩, SMOTE
from sklearn.preprocessing import StandardScaler, MinMaxScaler
from sklearn.preprocessing import PolynomialFeatures, LabelEncoder
from imblearn.over_sampling import SMOTE
# VIF 계산용 (다중공선성 확인용)
from statsmodels.stats.outliers_influence import variance_inflation_factor
실습 데이터 생성
프로젝트에서는 0번 절차는 생략됨.
0-1. 임의 데이터프레임 생성
- 수치형, 범주형, 날짜, 타깃 포함
# ----------------------------------------------------------
# 1) 임의 데이터프레임 생성
# - 수치형 변수 2개, 범주형 변수 1개, 날짜변수 1개, 타깃 변수(불균형) 1개
# ----------------------------------------------------------
np.random.seed(42)
N = 200
# 수치형 변수를 생성 (평균 50, 표준편차 10)
num1 = np.random.normal(loc=50, scale=10, size=N)
num2 = np.random.normal(loc=100, scale=20, size=N)
# 범주형 변수 (A, B, C 중 무작위)
cat_col = np.random.choice(['A', 'B', 'C'], size=N)
# 날짜변수(최근 200일 내 임의 날짜) 생성
date_rng = pd.date_range('2025-01-01', periods=N, freq='D')
print(date_rng)
#np.random.shuffle(date_rng) # 날짜 순서 랜덤화
# 불균형 타깃(1이 10%, 0이 90%라고 가정)
# - 실제로 1이 대략 20개, 0이 180개
target = np.random.choice([0,1], p=[0.9, 0.1], size=N)
# 데이터프레임 구성
df = pd.DataFrame({
'num1': num1,
'num2': num2,
'cat_col': cat_col,
'date_col': date_rng,
'target': target
})
0-2. 결측치 추가 & 이상치 주입
# ----------------------------------------------------------
# 2) 결측치 추가 & 이상치(Outlier) 주입
# - 일부 값을 NaN으로 바꾸고, 극단값 몇 개 삽입
# ----------------------------------------------------------
# (2-1) 결측치 추가
missing_indices_num1 = np.random.choice(df.index, size=5, replace=False) # 5개 결측
missing_indices_num2 = np.random.choice(df.index, size=5, replace=False) # 5개 결측
missing_indices_cat = np.random.choice(df.index, size=3, replace=False) # 3개 결측
missing_indices_date= np.random.choice(df.index, size=2, replace=False) # 2개 결측
df.loc[missing_indices_num1, 'num1'] = np.nan
df.loc[missing_indices_num2, 'num2'] = np.nan
df.loc[missing_indices_cat, 'cat_col'] = np.nan
df.loc[missing_indices_date,'date_col'] = pd.NaT
# (2-2) 이상치(Outlier) 주입: num1, num2에 극단값
outlier_indices_num1 = np.random.choice(df.index, size=3, replace=False)
outlier_indices_num2 = np.random.choice(df.index, size=3, replace=False)
df.loc[outlier_indices_num1, 'num1'] = df['num1'].mean() + 8*df['num1'].std()
df.loc[outlier_indices_num2, 'num2'] = df['num2'].mean() + 10*df['num2'].std()
print("=== [원본 데이터 일부] ===")
print(df.head(10))
print()# 결측치 있음을 확인
df.isnull().sum()1. 결측치 처리
# ----------------------------------------------------------
# 3) 결측치 처리
# (3-1) 일부 행 제거, (3-2) 평균·중앙값 등으로 대체
# ----------------------------------------------------------
df_dropna = df.dropna() # 모든 컬럼 중 결측값이 있으면 제거
df_fillna = df.copy()
# 수치형은 열별 평균으로 대체 (mean)
df_fillna['num1'] = df_fillna['num1'].fillna(df_fillna['num1'].mean())
df_fillna['num2'] = df_fillna['num2'].fillna(df_fillna['num2'].mean())
# 범주형은 최빈값으로 대체 (mode)
most_freq_cat = df_fillna['cat_col'].mode().iloc[0]
df_fillna['cat_col'] = df_fillna['cat_col'].fillna(most_freq_cat)
# 날짜열은 제거하지 않고 그대로 둠(또는 임의 날짜로 대체 가능)
# -> 시연을 위해 NaT(결측)도 남겨둠
print("=== [결측치 제거 후 shape] ===")
print(df_dropna.shape)
print("=== [결측치 대체 후 shape] ===")
print(df_fillna.shape)
print()
2. 이상치 제거
# ----------------------------------------------------------
# 4) 이상치 제거
# - (4-1) 표준편차 기준 (mu ± 3*std)
# - (4-2) IQR 기준
# ----------------------------------------------------------
# 결측치 제거를 한 데이터를 가져와서 진행
df_outlier_std = df_dropna.copy()
mean_num1, std_num1 = df_outlier_std['num1'].mean(), df_outlier_std['num1'].std()
mean_num2, std_num2 = df_outlier_std['num2'].mean(), df_outlier_std['num2'].std()
# 임계값 설정: ±3σ 사이의 범위가 정상 (벗어나면 이상, σ는 표준편차)
lower_num1, upper_num1 = mean_num1 - 3*std_num1, mean_num1 + 3*std_num1
lower_num2, upper_num2 = mean_num2 - 3*std_num2, mean_num2 + 3*std_num2
df_outlier_std = df_outlier_std[
(df_outlier_std['num1'] >= lower_num1) & (df_outlier_std['num1'] <= upper_num1) &
(df_outlier_std['num2'] >= lower_num2) & (df_outlier_std['num2'] <= upper_num2)
]
# (4-2) IQR 기반
df_outlier_iqr = df_dropna.copy()
Q1_num1 = df_outlier_iqr['num1'].quantile(0.25)
Q3_num1 = df_outlier_iqr['num1'].quantile(0.75)
IQR_num1 = Q3_num1 - Q1_num1
Q1_num2 = df_outlier_iqr['num2'].quantile(0.25)
Q3_num2 = df_outlier_iqr['num2'].quantile(0.75)
IQR_num2 = Q3_num2 - Q1_num2
low_num1 = Q1_num1 - 1.5*IQR_num1
up_num1 = Q3_num1 + 1.5*IQR_num1
low_num2 = Q1_num2 - 1.5*IQR_num2
up_num2 = Q3_num2 + 1.5*IQR_num2
df_outlier_iqr = df_outlier_iqr[
(df_outlier_iqr['num1'] >= low_num1) & (df_outlier_iqr['num1'] <= up_num1) &
(df_outlier_iqr['num2'] >= low_num2) & (df_outlier_iqr['num2'] <= up_num2)
]
print(f"=== [이상치 제거 전 shape] : {df_dropna.shape}")
print(f"=== [표준편차 기준 제거 후 shape] : {df_outlier_std.shape}")
print(f"=== [IQR 기준 제거 후 shape] : {df_outlier_iqr.shape}")
print()
# 정규분포를 가정한다면 표준편차를 활용한 제거가 낫겠으나, 그런 가정이 힘들다면 IQR 방식제거 선택!
3. 스케일링
# ----------------------------------------------------------
# 5) 스케일링: 표준화(StandardScaler), 정규화(MinMaxScaler)
# - 예시로 df_outlier_iqr 를 사용
# ----------------------------------------------------------
# 위에서 iqr 방식으로 이상치를 제거한 데이터를 가져와서 진행
df_scaled = df_outlier_iqr.copy()
# 표준화(StandardScaler)
scaler_std = StandardScaler()
df_scaled['num1_std'] = scaler_std.fit_transform(df_scaled[['num1']])
df_scaled['num2_std'] = scaler_std.fit_transform(df_scaled[['num2']])
# 정규화(MinMaxScaler)
scaler_minmax = MinMaxScaler()
df_scaled['num1_minmax'] = scaler_minmax.fit_transform(df_scaled[['num1']])
df_scaled['num2_minmax'] = scaler_minmax.fit_transform(df_scaled[['num2']])
print("=== [스케일링 결과 컬럼 확인] ===")
print(df_scaled[['num1','num1_std','num1_minmax','num2','num2_std','num2_minmax']].head())
print()🔍 StandardScaler : 평균이 0, 표준편차가 1 근처로 나오는지 확인
# StandardScaler : 평균이 0, 표준편차가 1 근처로 나오는 것을 확인 => 표준화가 제대로 진행됨
df_scaled[['num1_std', 'num2_std']].describe()
🔍 MinMaxScaler : 최소가 0, 최대가 1 인지 확인
# MinMaxScaler : 최소가 0, 최대가 1 로 나옴 => 정규화가 제대로 진행됨
df_scaled[['num1_minmax', 'num2_minmax']].describe()
4. 범주형 데이터 변환 (예외 : CatBoost)
# ----------------------------------------------------------
# 6) 범주형 데이터 변환 (원-핫, 라벨 인코딩)
# - 라벨 인코딩: cat_col
# - 원-핫 인코딩: cat_col (또는 라벨 인코딩 후 다른 DF에 적용 가능)
# ----------------------------------------------------------
df_cat = df_scaled.copy()
# (6-1) 라벨 인코딩 (예: 학점, 사이즈 등 순서가 있는 데이터에 사용)
label_encoder = LabelEncoder()
df_cat['cat_label'] = label_encoder.fit_transform(df_cat['cat_col'])
# (6-2) 원-핫 인코딩
df_cat = pd.get_dummies(df_cat, columns=['cat_col'])
print("=== [라벨 인코딩 + 원핫 인코딩 결과 컬럼] ===")
print(df_cat.head())
print()💡 cat_col -> cat_col_A / cat_col_B / cat_col_C 이렇게 3개가 새 변수로 만들어짐 (True=1, False=0)
변수가 3개일 때, 하나를 줄여도 문제가 안됨!

5. 파생변수 생성
# ----------------------------------------------------------
# 7) 파생변수 생성
# - (7-1) 날짜 파생: 연, 월, 요일, 주말여부 등
# - (7-2) 수치형 변수 조합
#
# ----------------------------------------------------------
df_feat = df_cat.copy()
# (7-1) 날짜 파생
df_feat['year'] = df_feat['date_col'].dt.year
df_feat['month'] = df_feat['date_col'].dt.month
df_feat['dayofweek'] = df_feat['date_col'].dt.dayofweek # 월=0, 화=1, ...
df_feat['is_weekend'] = df_feat['dayofweek'].apply(lambda x: 1 if x>=5 else 0)
# (7-2) 수치형 변수 조합 예시: num1 + num2
df_feat['num_sum'] = df_feat['num1_std'] + df_feat['num2_std']
print("=== [파생 변수 생성 결과] ===")
print(df_feat[['date_col','year','month','dayofweek','is_weekend','num1','num2','num_sum']].head())
print()
6. 다중공선성 확인
# ----------------------------------------------------------
# 8) 다중공선성 확인 (상관관계, VIF)
# - 예시로 수치형 변수(num1, num2, num_sum, num1_log 등)만 확인
# ----------------------------------------------------------
df_corr = df_feat[['target', 'num1_std', 'num2_std', 'cat_label', 'year', 'month', 'dayofweek', 'is_weekend', 'num_sum']].dropna()
print("=== [상관계수] ===")
print(df_corr.corr())
# VIF 계산 함수
def calc_vif(df_input):
vif_data = []
for i in range(df_input.shape[1]):
vif = variance_inflation_factor(df_input.values, i)
vif_data.append((df_input.columns[i], vif))
return pd.DataFrame(vif_data, columns=['feature','VIF'])
vif_df = calc_vif(df_corr)
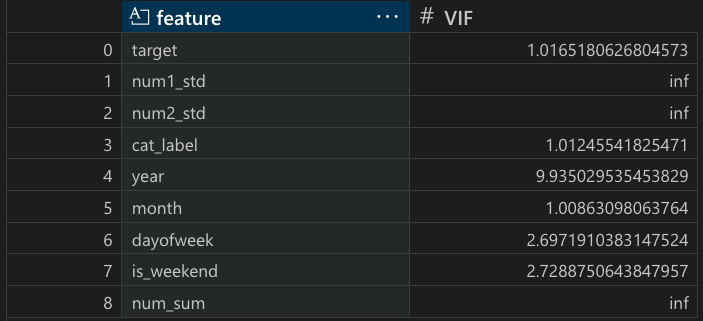
print("\n=== [VIF 결과] ===")
print(vif_df)
print()
# year는 모든 데이터가 동일한 연도여서 nan으로 나타남🧐 target(종속변수) 없이 독립변수만 상관관계를 확인!
df_corr.corr()
# 원래는 target(종속변수)없이 독립변수만 상관관계를 확인한다. 강의에서 편하게 다 보여주기 위해 같이 결과를 냄🚨 num1_std, num2_std, num_sum 은 서로 연관되어 있기 때문에 무한대로 나옴 (num1_std + num2_std = num_sum 관계)
7. 불균형 데이터 처리
# ----------------------------------------------------------
# 9) 불균형 데이터 처리: SMOTE
# - 타깃이 [0,1]로 되어 있고, 1이 매우 적은 상태
# - SMOTE 적용 위해선 '피처'와 '타깃' 분리 필요
# ----------------------------------------------------------
df_smote = df_feat.copy().dropna(subset=['target']) # 일단 이상치,결측 제거된 DF 사용
# 독립변수와 종속변수를 분리!!
X = df_smote[['num_sum', 'cat_label', 'year', 'month', 'dayofweek', 'is_weekend']] # 간단히 수치형 2개만 피처로
y = df_smote['target']
# ⭐️범주, 클래스, 항목 등을 예측할 때, SMOTH 같은것을 사용함 (연속적인 수치형인 경우, SMOTH 사용X : 분류 -> 정상/이상, 양성/음성 구분)
# 매출값 같은 경우에는 균등한지 아닌지 판단하기 쉽지 않음, 자유롭기 때문에, SMOTH 사용X
print("=== [SMOTE 전 레이블 분포] ===")
print(y.value_counts())
sm = SMOTE(random_state=42)
X_res, y_res = sm.fit_resample(X, y)
print("=== [SMOTE 후 레이블 분포] ===")
print(pd.Series(y_res).value_counts())
print()✔️ 결과 확인


끝.
'머신러닝' 카테고리의 다른 글
| [ML] 머신러닝 4강 - 값을 예측하고 싶을 땐 회귀 (0) | 2025.11.18 |
|---|---|
| [ML] 2강 - 머신러닝을 위한 전처리 이론 (1) | 2025.11.17 |
| [ML] 1강 - 머신러닝이란? (0) | 2025.11.17 |