

머신러닝이란?
인간의 개입 없이(또한 최소한으로) 데이터를 학습하여
패턴을 찾아내고, 새로운 데이터에 대해 예측이나 분류를 수행하는 기술
예) 스펨 메일 필터링, 이미지 분류, 음성 인식 등
머신러닝의 3대 요소
- 데이터 : 양과 질 모두 중요, 정보의 모음
- 알고리즘 : 머신러닝 그 자체, 문제해결을 위해 순서대로 처리하는 방법이나 규칙 (= 모델)
- 컴퓨팅 파워 : 얼마나 빠르고 많이 일(연산)이 가능한지 나타내는 능력치 ( + 딥러닝에 관심 있다면 중요해짐)
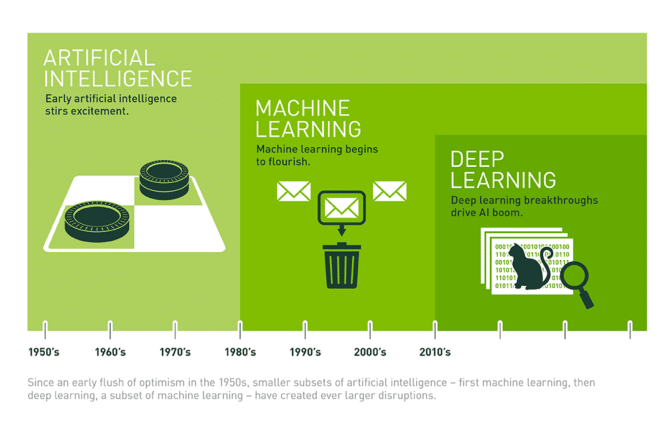
머신러닝, AI, 딥러닝의 관계
- 인공지능(AI) : 사람의 지능적인 작업을 기계가 수행
- 머신러닝(ML) : 데이터로부터 특징이나 규칙을 찾아내 학습하는 것
- 스펨메일의 특징이나 공통점(패턴)을 찾아 자동으로 분류
- 딥러닝(DL) : 사람의 뇌신경을 본 떠 만든 인공신경망으로 이루어짐. 여러 겹 쌓아서 복잡한 정보 학습
- ChatGPT, 알파고, DALL_E, 딥시크 등등
머신러닝의 역할 및 중요성
⭐️ 대량의 데이터 처리와 분석(빠르고 정확하게), 복잡한 상관관계 발견/예측
활용 분야
📌 제조업
센서 데이터 수집 -> 설비 이상 징후 예측, 품질 불량 예측
자동화된 공정 제어 및 유지 보수 비용 절감
- 예측 유지 보수 : 설비에 부착된 설비(온도, 진동 등)에서 수집된 데이터 활용하여 징후 예측
- 품질 관리
- 생산 공정 최적화
- 수요 예측
- 에너지 효율 최적화 : 최대한 에너지를 적게 사용, 낭비되는 부분 최소화, 적절히 에너지 공급
📌 금융
신용카드 사기 거래 탐지, 대출 리스크
알고리즘 트레이딩(주식 자동 매매)
- 신용 평가 : 돈을 잘 갚을 수 있는지를 점수로 매기는 과정, 과거금융 기록, 소득, 직장정보 바탕
( 최근 대안데이터 활용, sns, 구매이력 등 )
- 위험관리 : 손실 위험 계산, 미리 대비
- 자산운용 및 투자전략 : 알고리즘 트레이딩 -> 자동으로 주식 매매 / 로보어드바이저 -> 자산 배분, 자동 추천
- 고객 서비스 자동화(챗봇, 가상 상담사)
- 보험 업무 고도화(언더라이팅, 청구 자동화 등) : 보험사가 어떤 조건(보험료, 보장 범위 등)으로 보험을 팔지 결정하는 과정
📌 헬스케어
질병 진단(영상, 유전자 분석), 환자 상태 예측
📌 마케팅
고객 세분화, 구매 패턴 분석, 타겟 마케팅
- 고객 세분화 & 페르소나 도출
비슷한 취향, 행동을 하는 사람들끼리 그룹화
가상 인물을 설정해 구체적으로 이해하려는 방법
- 추천 시스템 : 마케팅 캠페인 성과 예측 : 과거 캠페인 데이터와 고객반응 데이터로 향후 성과 예측
- 고객 생애 가치(LTV) 예측 : 한 명의 고객이 우리 회사와 거래하는 동안 가져다주는 수익을 예측
📌 자율주행
카메라, 라이다 등을 통한 실시간 도로 상황 분석 -> 의사결정
■ 머신러닝 vs 통계 분석 : 차이가 뭔데?
- 통계분석은 주로 "왜?"라는 것에 집중 / 가설 검증, 추론 ( 변수들 간의 유의한 관계가 있어? )
- 머신러닝은 예측하고 얼마나 "잘할지"에 집중 (✔️ 정확도, 재현율 등)
데이터가 많아질수록
통계 : 더 정교한 추론은 가능 but, 가설 자체는 사람이 세움
머신러닝 : 학습에 유리, 더 좋은 모델을 만들 수 있음
머신러닝의 종류
학습 종류에 따라 세 가지로 나눔.
지도학습
우리가 맞다고 알고 있는 결과값을 정답값(레이블) -> 학습
1. 분류(classification) : 어느 그룹에 속하는지를 결정 (스펨여부, 대출상환 가능여부)
2. 회귀(regression) : 숫자로 된 결과를 예측 (주택가격예측, 주가예측)
비지도 학습
레이블(정답값) 없이 패턴을 스스로 찾음
1. 군집화(clustering) : 성향이 비슷한 사람이나 사물을 자동으로 묶어내는 기법 (고객군집 분석, 문서 토픽 분석)
2. 차원 축소(dimensionality reduction) : 데이터의 특징(변수)이 너무 많아서 복잡한 데이터를 핵심 정보만 남기고 압축하는 기법, 중심문장 요약(나만의 언어로 요약해서 압축) / 전처리, 시각화에도 활용
<-> 변수 선택 : 많은 특징(변수) 중 몇 개만 뽑아서 가져오는 것
▼ 사진

- 강화학습(참고)
: 게임, 전략 등에 활용

에이전트가 환경과 상호작용하며 보상(reward)을 최대화하도록 학습
게임으로 치면,
- 에이전트 : 플레이어
- 환경 : 맵, (메이플, 오르비스를 가기위해 배를 탐 -> 크림슨 발록이 나타남)
- 보상 : 크림슨 발록을 잡으면 보상과 경험치, 죽으면 불이익 개념
즉, 가장 높은 보상을 보장해주는 행동 규칙(전략)을 학습함
머신러닝 모델링 프로세스
데이터 수집부터 배포까지
✔️ 데이터 수집
: 웹크롤링, 센서측정, 설문조사, DB추출 등
: 양질의 데이터 확보가 중요 (제조업에서는 공정 라인에 설치된 IoT센서에서 데이터 지속 수집)
✔️ 전처리 (정말 중요⭐️⭐️⭐️⭐️⭐️)
1. 결측치 처리
: 결측치 X
: 빈 칸을 평균이나 가장 빈도가 높은 값으로 대체 또는 필요하면 빼고(삭제) 분석
2. 이상치 처리
: 데이터 범위에서 심하게 벗어난 값을 해결 (몸무게 50 - 100kg 인데 500kg라면?)
3. 스케일링 ( 정규화, 표준화)
: 각각 다른 단위를 쓰는 데이터를 비슷한 수준으로 맞춰주는 작업
: 각 지표의 범위를 0-1 사이 값으로 부여 -> 공평하게 다룰 수 있음(정규화)
4. 범주형 변환
: 글자로 된 정보를 숫자로!
: 예)원-핫 인코딩(순서X, 색깔..), 레이블 인코딩(순서0 데이터에 사용, 사이즈M/L/XL..) 등
* 예외) 범주형 변환을 안해도 되는 것 -> Catboost
✔️ 모델링(Modeling)
- 지도학습 : 분류/회귀
- 로지스틱 회귀, 랜덤 포레스트, XGBoost 등
- 비지도학습 : 클러스터링/차원축소
- K-Means, PCA 등
✔️ 성능 평가 (경우에 따라서 굉장히 많음)
1. 분류 : accuracy, precision, recall, f1-score, roc_auc 등
2. 회귀 : MAE, RMSE, R^2 등
3. 비지도(군집) : 실루엣 계수 등
-> 이후 모델링 ✔️ 배포!(엔지니어의 영역)
모델링 프로세스 요약
: 데이터 수집 -> 전처리 -> 모델링 -> 평가 -> 최적화 -> 배포
+ 추가 학습
윤리적 이슈 & 데이터 편향(Bias)
데이터 편향
: 머신리닝은 데이터를 보고 학습을 하기 때문에
✔️ 데이터는 편향이 되지 않도록!! ( 인종/성별 분포가 편향된 데이터 -> 차별적 의사결정 )
윤리적 책임
: 편향 줄이기 위해 데이터 균형화
: 민감 정보 보호(개인정보 비식별화)
📌 실무 TIP
: 잘 정리된 데이터가 80%
: 모델링과 튜닝은 20% 미만
: 현업에선 도메인지식 + 머신러닝 지식의 협업 필수
'머신러닝' 카테고리의 다른 글
| [ML] 머신러닝 4강 - 값을 예측하고 싶을 땐 회귀 (0) | 2025.11.18 |
|---|---|
| [ML] 3강 - 머신러닝을 위한 전처리 실습 (0) | 2025.11.17 |
| [ML] 2강 - 머신러닝을 위한 전처리 이론 (1) | 2025.11.17 |