

1. 출력값은?
START WITH COL3 = 4
CONNECT BY COL1 = FRIOR COL2;
➡️ START WITH 절부터 시작하고, 그 다음 CONNECT BY 절을 따라감
전행의 COL2와 현행의 COL1 이 같아야 한다는 뜻
2. 다른 것은?
(인수1, 인수2)일때
IFNULL(NULL, 'A') : 인수1이 NULL 일 때, 인수2 반환(mysql버전)
NVL(NULL, 'A') : 인수1이 NULL 일 때, 인수2 반환(oracle버전)
COALESCE(NULL, 'A') : NULL이 아닌 최초의 인수를 반환 (인수1, 인수2, 인수3, 인수4 ,,,,,, )
NULLIF(NULL, 'A') : 인수1과 인수2가 같으면 NULL, 같지 않으면 인수1을 반환 (null 반환하지만 실제론 에러발생)
3. DDL문 표현
STUDENT 테이블의 name 컬럼의 조건을 not null로 변경
➡️ ALTER TABLE student MODIFY (NAME NOT NULL);
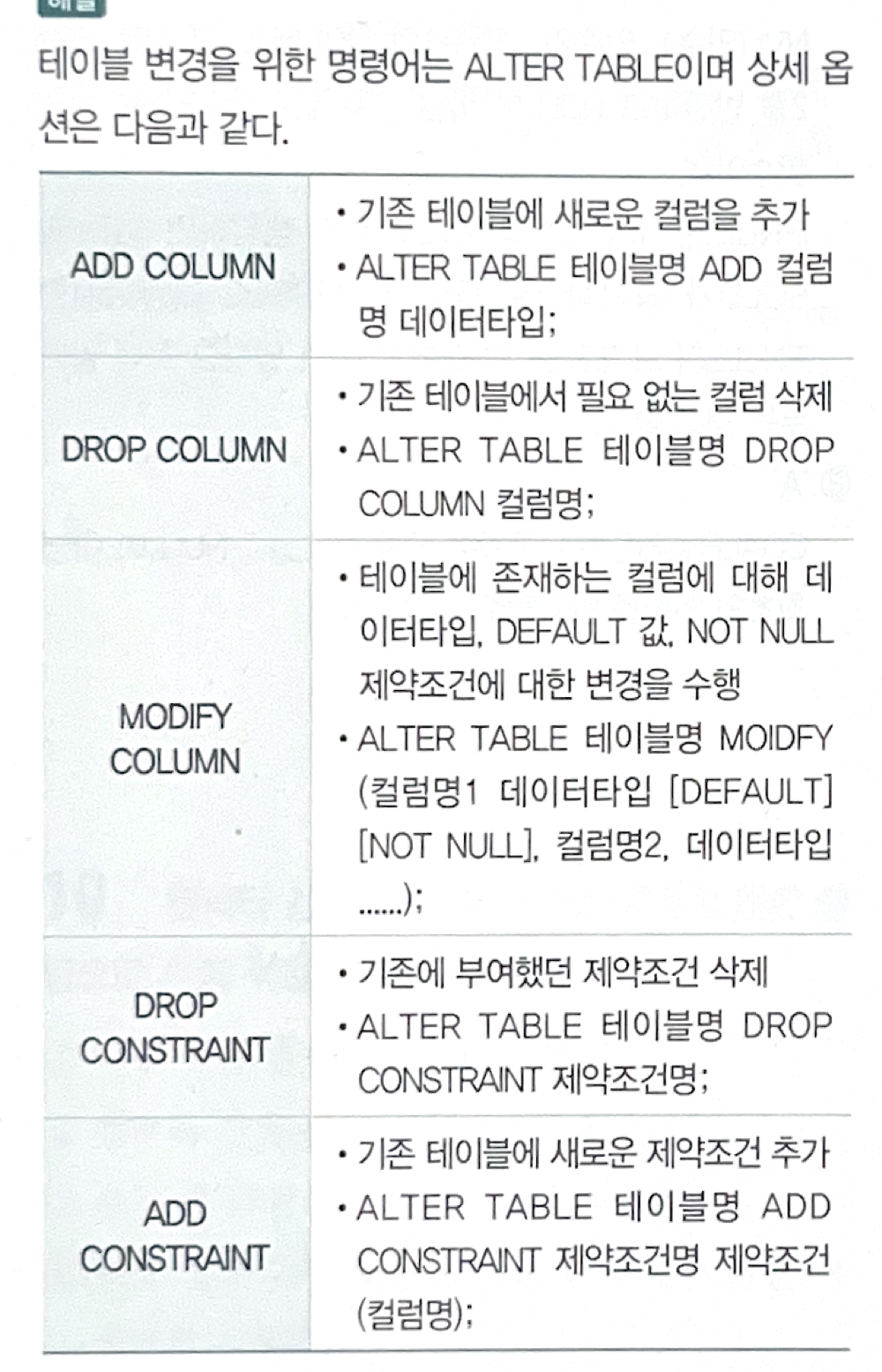
4. 집계
[SQL] GROUP BY CUBE(DEPTNO, JOB); 와 동일한 결과는?
➡️ GROUP BY GROUPING SETS(DEPTNO, JOB, (DEPTNO, JOB), ());
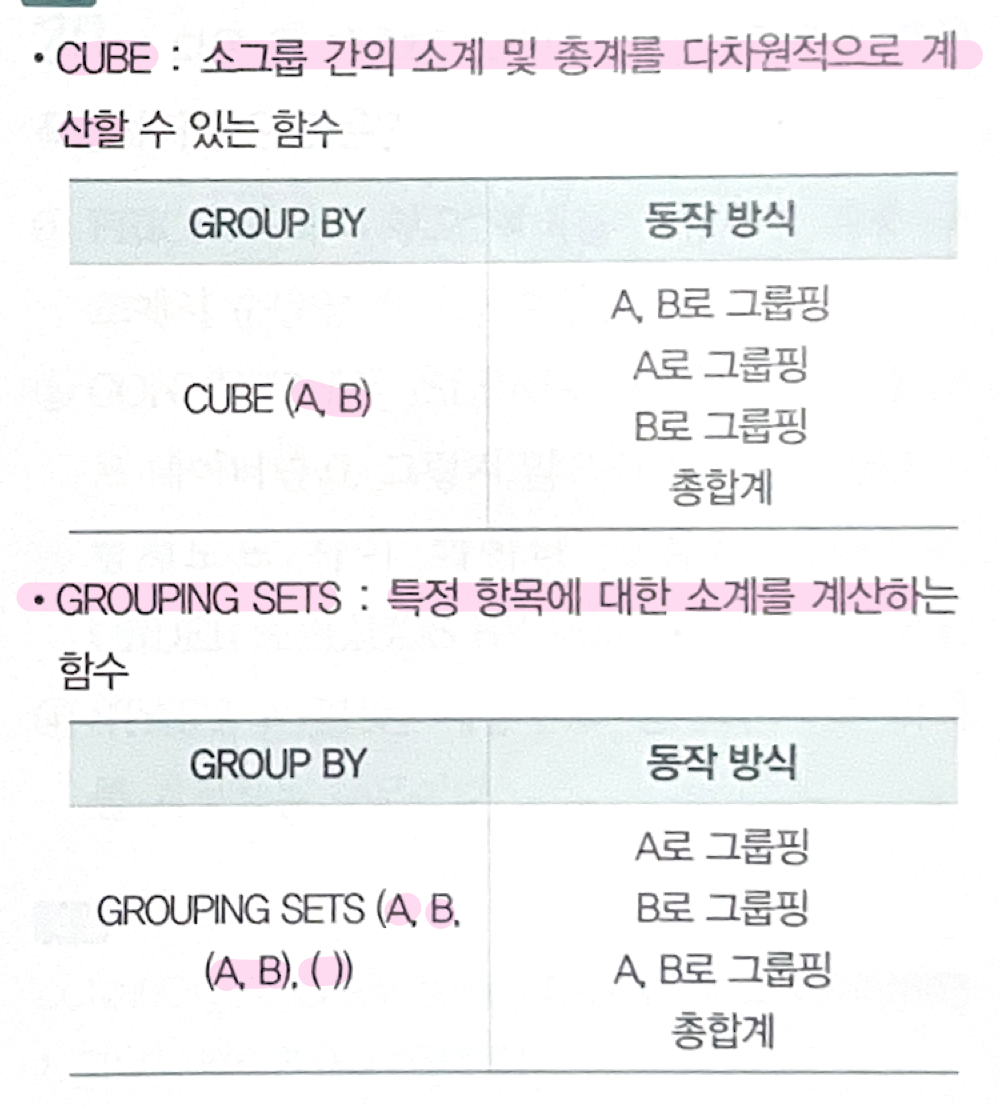
5. 결과가 다른것?
[COL1 = 10, NULL, 20]
NVL(SUM(COL1), 0) ➡️ 인수가 null일 경우 0 이라고 처리를 했으므로 0
MIN(COL1)
MAX(COL1)
AVG(COL1)
➡️ 나머지는 모두 NULL
: 해당컬럼 내 null 값이 있을 경우, 집계함수 sum, min, max, avg는 null 임!!


✔️ 전자는 10(sum 집계할 때 null을 제외하고 계산), 후자는 null(null은 비교 및 계산 자체 불가)
6. 윈도우 함수에 대한 설명
ROW_NUMBER() : 동일 순위는 동일값 부여 ➡️ 동일 순위에도 다른 값을 부여함
RANK() : 동일 순위는 동일값 부여
FIRST_VALUE(NAME) : 첫 번째 행의 이름 데이터
* RANGE UNBOUNDED PRECEDING : 첫 번째 행부터 현재 행까지
7. WHERE EXISTS ( 서브쿼리 ) 는 중복된 데이터가 모두 출력된다.
8. Oracle에서는 group by 절에서 select 절의 별칭을 사용할 수 없다.
9. 가장 적절하지 않은 것은?
데이터 입력후 ROLLBACK 시 데이터 입력이 취소된다.
테이블 생성 후 ROLLBACK 시 테이블 생성이 취소된다.
데이터 삭제 후 ROLLBACK 시 데이터가 다시 부활한다.
데이터 변경 후 ROLLBACK 시 데이터가 이전 상태로 돌아간다.
➡️ DDL (create, alter, drop, rename)의 경우 자동 커밋(auto commit)이 되기 때문에 ROLLBACK이 불가능함.
10. SUBSTR('문자열', A, B) : 문자열의 A번째 부터 B개 불러와. (-A일 경우 오른쪽에서 A번째부터 B개 가져와)
11. 트랜잭션의 특성

12. SELF JOIN으로 계층형 쿼리를 만들 수 있다.
13. LIKE 구문을 사용하여 데이터에 "%"가 포함된 문자열을 찾는 SQL문은?
➡️ SELECT * FROM SQLD_38 WHERE COL1 LIKE '%@%%' ESCAPE '@';
ESCAPE로 특정 문자를 지정한 뒤 '%'나 '_' 앞에 붙여서 작성
밑줄 친 부분이 문자 그대로의 '%'를 의미하며, 문자에 '%'가 포함된 문자를 출력하게 됨.
14. 계층형 쿼리의 내장함수
LEVEL
CONNECT_BY_ISLEAF
CONNECT_BY_ISCYCLE
SYS_CONNECT_BY_PATH
CONNECT_BY_ROOT
NOCYCLE 등이 있음
아닌 것은 BLEVEL
15. 결과가 다른 SQL은?
COL1 = [ 1, 2, NULL, 4, 5 ]
SELECT COUNT(1) FROM SQLD_44;
SELECT COUNT(2) FROM SQLD_44;
SELECT COUNT(*) FROM SQLD_44;
✔️ SELECT COUNT(COL1) FROM SQLD_44; ➡️ NULL인 행을 제외하고 행의 수를 출력!!
16. SQL은 다음과 같이 분류된다.

* 추가
ROLLUP(컬럼1, 컬럼2)과 CUBE(컬럼1, 컬럼2) 이해하기
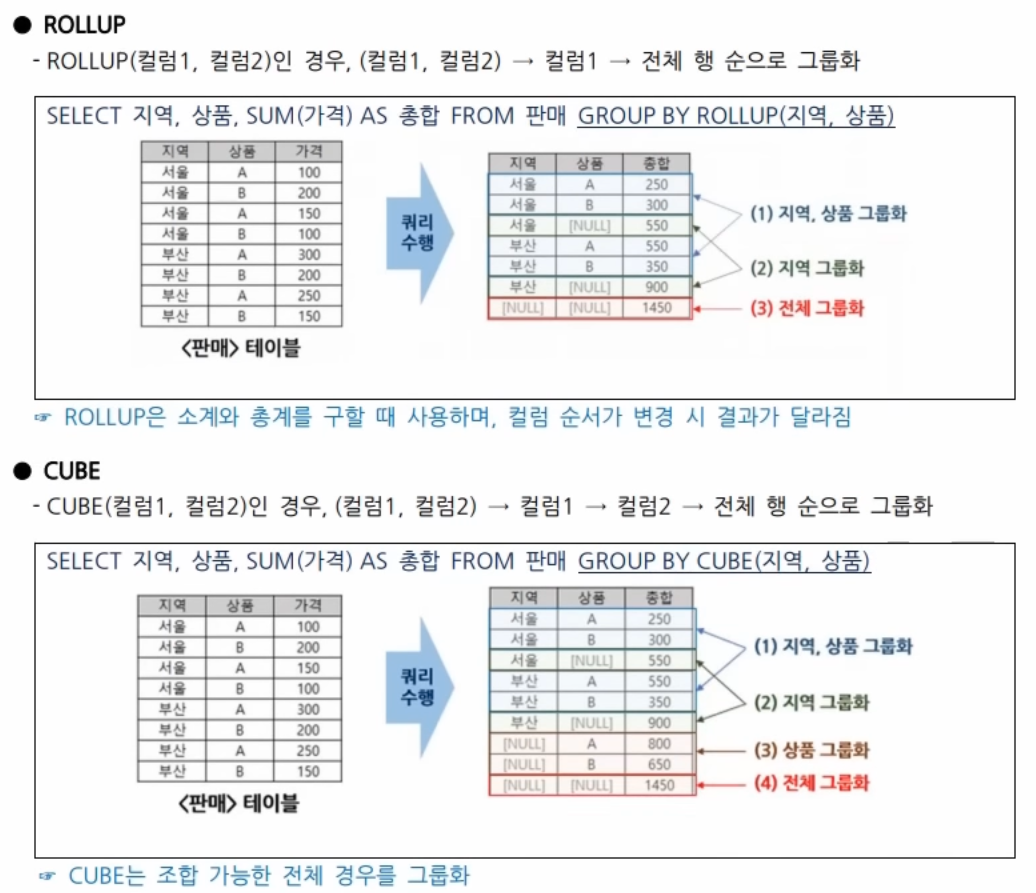
PIVOT과 UNPIVOT

'자격증 > SQLD' 카테고리의 다른 글
| [SQLD] 기출로 본 1과목 핵심 개념 (0) | 2025.11.12 |
|---|