

프로젝트 진행 현황
- 개인 : 데이터셋 탐색 / 전처리 / EDA 1차
- 팀 : 개인이 진행한 부분 공유 및 정리
개인 진행 상황
- 어려웠던 점 : 여전히 전처리 과정이 어렵게 느껴졌다.
삭제 컬럼 선정 관련
일단 컬럼의 수가 많기 때문에 어떤 컬럼을 사용할지 사용하지 않을지가 분명하지 않았기 때문에 더욱 어렵게 느껴졌던 것 같다. 오늘은 삭제하지 않고 사용할 컬럼만 뽑아서 사용하는 것에 그쳤다.
결측치 처리 전략 관련
다음으로, 결측치 처리 전략을 세우는 과정이 아직은 수월하지는 않지만, 지난 번 많은 시행착오를 겪었던 부분이기도 하고 결측치는 수치형과 범주형을 나누어 확인하였고, 추가 진행할 예정이다.
확인해본 내용들
1. 날짜컬럼 형식 : object -> datetime 변환
# 기존 object에서 datetime으로 변환 시도
df['first_review'] = pd.to_datetime(df['first_review'])
df['last_review'] = pd.to_datetime(df['last_review'])
df['host_since'] = pd.to_datetime(df['host_since'])
# 현재 데이터타입 확인
print(f"현재 first_review의 type : {df['first_review'].dtype}")
print(f"현재 last_review의 type : {df['last_review'].dtype}")
print(f"현재 host_since의 type : {df['host_since'].dtype}")모두 datetime으로 변환 확인했음.
2. 가격(핵심컬럼) 컬럼 형식 변환 : object -> int
기존 가격 컬럼 내용 예: $2,000.00(object) -> 2000(int)
# 가격 분포는 어떻게 나타나지?
# price 컬럼타입 : object
# 가격 앞에 $ 가 붙어있네? 지우고 수치형으로 바꿀수 있지 않을까?
# str. 문자열 매서드를 활용해서 없애볼까?
df['price'] = df['price'].str.replace('$', '').str.strip()
# 쉼표가 있으면 데이터타입 변환이 안된다네? 숫자만 남겨두도록 해보자
# df['price'].str.replace(',','', regex=False)
# # 이제 데이터타입 바꿔볼까?
# df['price'] = df['price'].astype(float) 🚨 계속 시도해도 오류
df['price'] = pd.to_numeric(df['price'].str.replace(',',''), errors='coerce')
# 이 셀에서는 price의 dtype은 float
# float 에서 int로 변환 시도
df['price'] = df['price'].astype(int)
df['price']
print("price의 type :", df['price'].dtype)
3. host_is_superhost
- 확인한 이유 : "슈퍼호스트가 아닌 호스트 보다 금액적으로 유리하지 않을까"하는 궁금증 💭
- 새로운 파생변수 '슈퍼호스트 여부' 생성
- values를 't' -> '슈퍼' & 'f' -> '일반'으로 mapping
4. instant_bookable
- 확인한 이유 : "즉시예약이 가능한 숙소 일수록 금액적으로 유리하지 않을까"하는 궁금증 💭
- 새로운 파생변수 '즉시예약 가능여부'로 생성
- values를 't' -> '가능' & 'f' -> '불가능' mapping
이렇게 정리를 했고, price 컬럼은 아래와 같이 히스토그램과 박스플랏을 뽑아보았다.
# price<=500 : 대략적인 분포를 보기 위해 500 이하인 것으로 확인했다.
price_500 = df.loc[df['price'] <= 500] # 데이터프레임
# 시각화 : 히스토그램
sns.histplot(data=price_500, x='price', bins=50, kde=True)
plt.title("가격에 따른 분포 (Price<=500)")
plt.xlabel("Price")
plt.ylabel("숙소 분포")
plt.show()
# 시각화 : 박스플랏
sns.boxplot(data=price_500, x='price', color='skyblue')
plt.title("가격 boxplot (Price<=500)")
plt.xlabel("Price")
plt.show()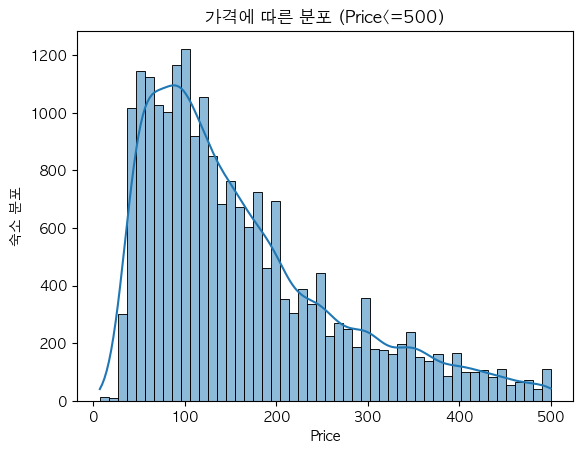
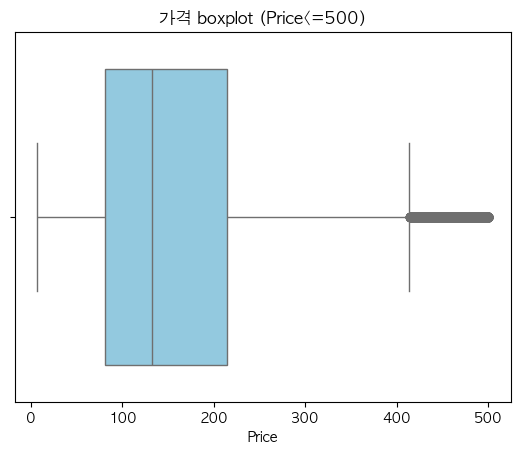
그래프를 해석해보면,
- price가 100에서 200 사이인 숙소가 대부분을 차지하고 있다.
- 금액대가 높아질수록 숙소의 분포도 줄어든다.
팀 진행 및 결정 사항
- 개인이 진행한 전처리/EDA 내용 공유
- 작성한 코드 내용을 노션에 복사하려 했으나, 구글드라이브 폴더에 공유하는 것으로 변경
- 데이터 컬럼이 많다보니, 설정한 주제에 사용되지 않을 컬럼 제외 확정!!
▼ 세부내용
📊 주요 컬럼(총 33개 중 16개 컬럼)
🙎🏻♀️ 호스트 관련
| 컬럼명 | 설명 | 빼야 하는 것 |
| host_id | 호스트 ID (Airbnb에서 부여한 고유 식별자) | |
| host_name | 호스트 이름 | X |
| host_since | 해당 호스트가 Airbnb에 가입한 날짜 | X |
| host_location | 호스트가 기입한 위치 | X |
| host_response_time | 호스트가 메시지에 응답하는 데 걸리는 평균 시간 | △ |
| host_response_rate | 호스트의 응답률 | △ |
| host_acceptance_rate | 예약 요청 수락률 | △ |
| host_is_superhost | 슈퍼호스트 여부 (True, False) | |
| host_listings_count | 호스트의 전체 등록 숙소 수 | X |
| host_identity_verified | 신원 인증 여부 (True, False) |
📍 위치 관련
| 컬럼명 | 설명 | 빼야 하는 것 |
| neighbourhood | 숙소가 속한 동네 | X |
| neighbourhood_group_cleansed | 정제된 대분류 지역명 (예: Manhattan, Brooklyn 등) | |
| latitude, longitude | 위도, 경도 좌표 | X |
🏠 숙소 정보
| 컬럼명 | 설명 | 빼야 하는 것 |
| property_type | 숙소 유형 (ex: 아파트, 집, 호텔 등) | |
| room_type | 방 종류 (Entire home/apt, Private room, Shared room) | |
| accommodates | 숙소 수용 가능 인원 | |
| bedrooms | 침실 개수 | |
| beds | 침대 개수 | |
| bathrooms | 욕실 수 | |
| amenities | 편의시설 목록 (JSON 형식) |
💰 가격 및 예약
| 컬럼명 | 설명 | 빼야 하는 것 |
| price | 1박 기준 숙박료 | |
| minimum_nights / maximum_nights | 최소 / 최대 숙박일 수 | |
| availability_365 | 1년 중 예약 가능한 일수 | |
| instant_bookable | 즉시 예약 가능 여부 (True, False) |
⭐ 리뷰 및 평점
(호스트가 가격을 위한 컨트롤 불가. 비가격적 요인(횟수 및 매출 증대 요인))
review_cols 로 따로 놔두고 삭제는 하지말자 (전처리에선 빼고) (리뷰 아닌 애들은 그냥 cols)
| 컬럼명 | 설명 | 빼야 하는 것 |
| number_of_reviews | 총 리뷰 수 | △ |
| reviews_per_month | 월별 평균 리뷰 수 | △ |
| review_scores_rating | 전반적 평점 | △ |
| review_scores_cleanliness | 청결도 평점 | △ |
| review_scores_communication | 커뮤니케이션 평점 | △ |
| first_review / last_review | 첫/마지막 리뷰 날짜 | △ |
- 기존에 프로젝트 진행 절차를 전처리/EDA 과정을 번갈아가며 진행하다보니, 각자 전처리 과정에서 파생되는 변수나 컬럼 등의 취합이 어려울 것으로 의견이 수렴했다. 그래서 전처리 과정을 마무리 하고 나서, 저장한 파일로 EDA 를 진행하기로 했다.
- 이에 따라 세부 일정을 조정하였음
✍️ 오늘의 회고
당면한 문제의 원인을 명확히 알고 비즈니스 목표를 명확히 해야 분석 방향을 설정할 수 있으며, 그에 따른 결측치 처리 방향도 달라진다는 점을 다시 한 번 깊이 깨닫게 된 시간이었다. 삭제 컬럼을 확정으니, 내일은 그걸로 제대로 전처리를 진행해보자! 그리고 통계적으로 어떤 검정을 진행할 수 있을지 분석 목적에 맞게 고민해보도록 하겠다.
'프로젝트' 카테고리의 다른 글
| [프로젝트 #2-3] 알아도 끝이 없는 결측치 처리, 오늘은 무엇이? 🔍 (1) | 2025.10.15 |
|---|---|
| [프로젝트 #2-1] 주제 선정 및 컬럼 확인을 해보았더니...👀 (1) | 2025.10.13 |
| [기초 프로젝트] 발표 후 피드백을 적어보았다...✍️ | 새롭게 알게된 개념 정리(feat. 구글AI) (3) | 2025.09.12 |