

📌 언제 각 검정을 사용하는지 이해하는 게 중요함!!!
가설검정
ANOVA (Analysis of Variance, 분산분석)
집단이 3개 이상의 집단의 평균을 비교할 때 사용
비교하는 과정에서 분산이 쓰이므로 분산분석으로 표현
ANOVA의 원리
일원분산분석, one-way ANOVA)
집단 내에서 분산과 집단 간의 분산을 비교하는 방식.
집단 내 분산 < 집단 간 분산 → 집단 간 차이가 있다고 판단

⬅️ 이게 사실 전부!!!
가설
- 귀무가설(H0) : 모든 집단의 평균이 같다.
- 대립가설(H1) : 적어도 하나의 집단 평균은 다르다.
예시 ▼
A 집단 내 차이보다 A, B, C 집단 간 차이가 더 크다???
- 그러면 적어도 하나의 집단 평균은 다르다!!(대립가설)

ANOVA 종류

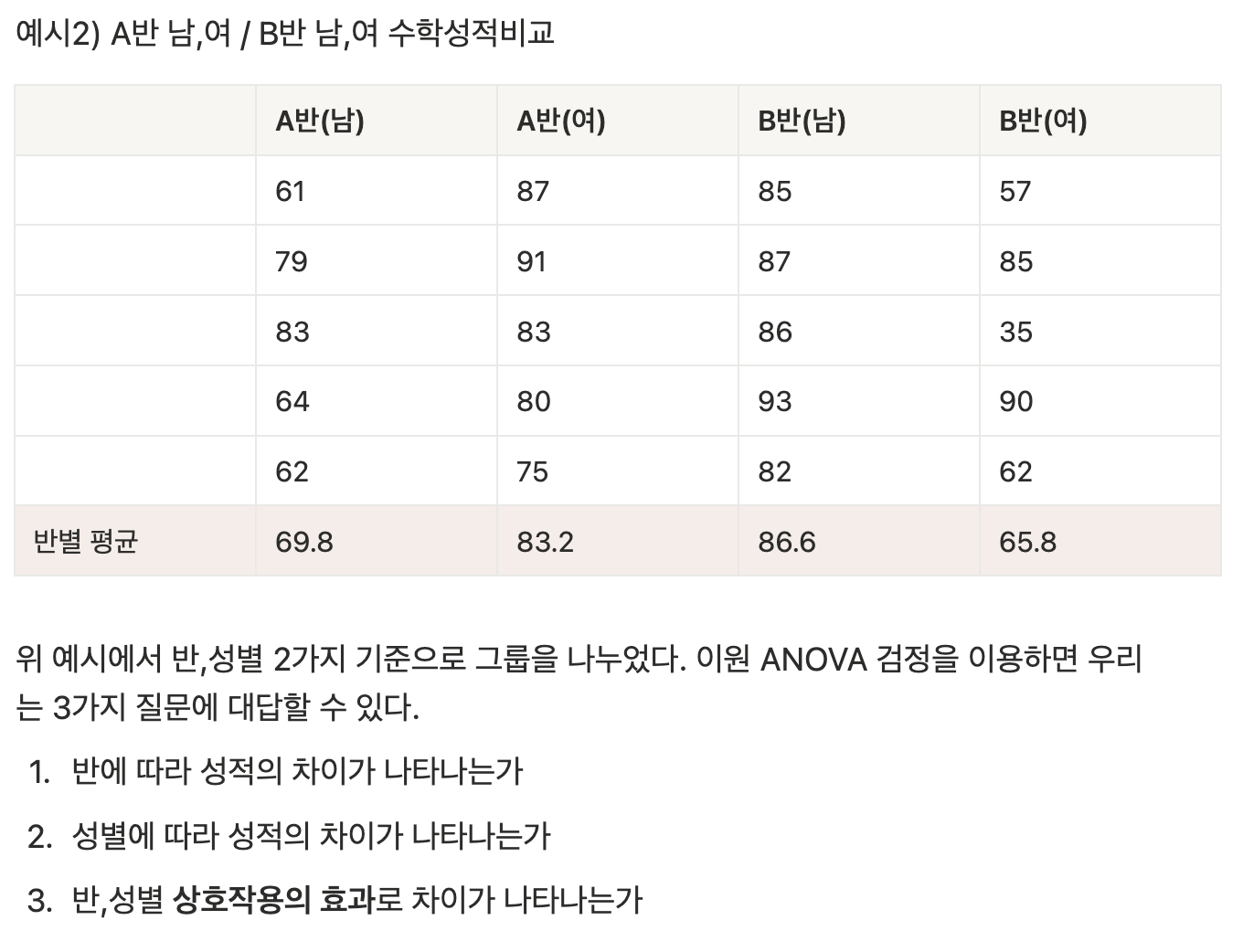
이원 ANOVA (two-way ANOVA)
그룹을 나누는 기준이 2가지
2가지 기준으로 나눈 뒤 각 기준으로 인해 차이가 발생하는지,
두 기준의 상호작용 효과로 차이가 발생하는지를 확인
예시 ▼
자동적으로 가설이 3가지 생김.

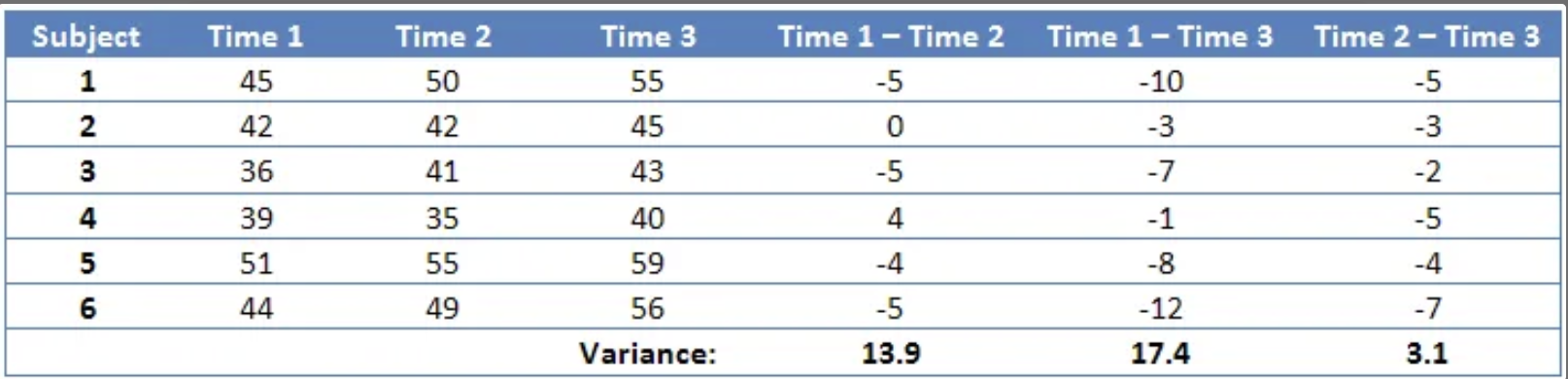
반복층정 ANOVA (RM ANOVA, Repeated measure)
대응표본 t-검정과 비슷하게 한 집단을 대상으로 여러 번 데이터를 구해서 차이를 비교하는 검정 방법
예시 ▼
예를들어, 같은 사람을 대상으로 조건이 달라질 경우, 반복측정 아노바!!
(식단 A, B만 비교한다면 대응표본 t-검정을 하고, ) 식단 A, B, C 3가지를 비교하면 반복측정 아노바!!
행별로 같은 사람이야. 근데 조건이 달리해서 하는 거야.

ANOVA 검정의 전제조건

- 독립성은 데이터 수집 단계에서 만족되어야 함. 별도 검정 ❌
- 구형성은 "각 데이터의 차이의 분산도 서로 같아야 한다." 라는 것 ( ⬅️ 반복측정 아노바 에서만 가능! )
- Mauchly's test 에서 p-value가 작으면,
✅ 즉, 모든 조건 간 차이의 분산이 같아야 한다.
표 참고 ▼
사후검정
아노바 검정은 차이의 유무만 확인할 수 있기 때문에,
📌 어느 집단끼리 차이가 발생했는지 알기 위해 사후 검정의 절차가 필요함!!

사후검정 방법 참고 ▼

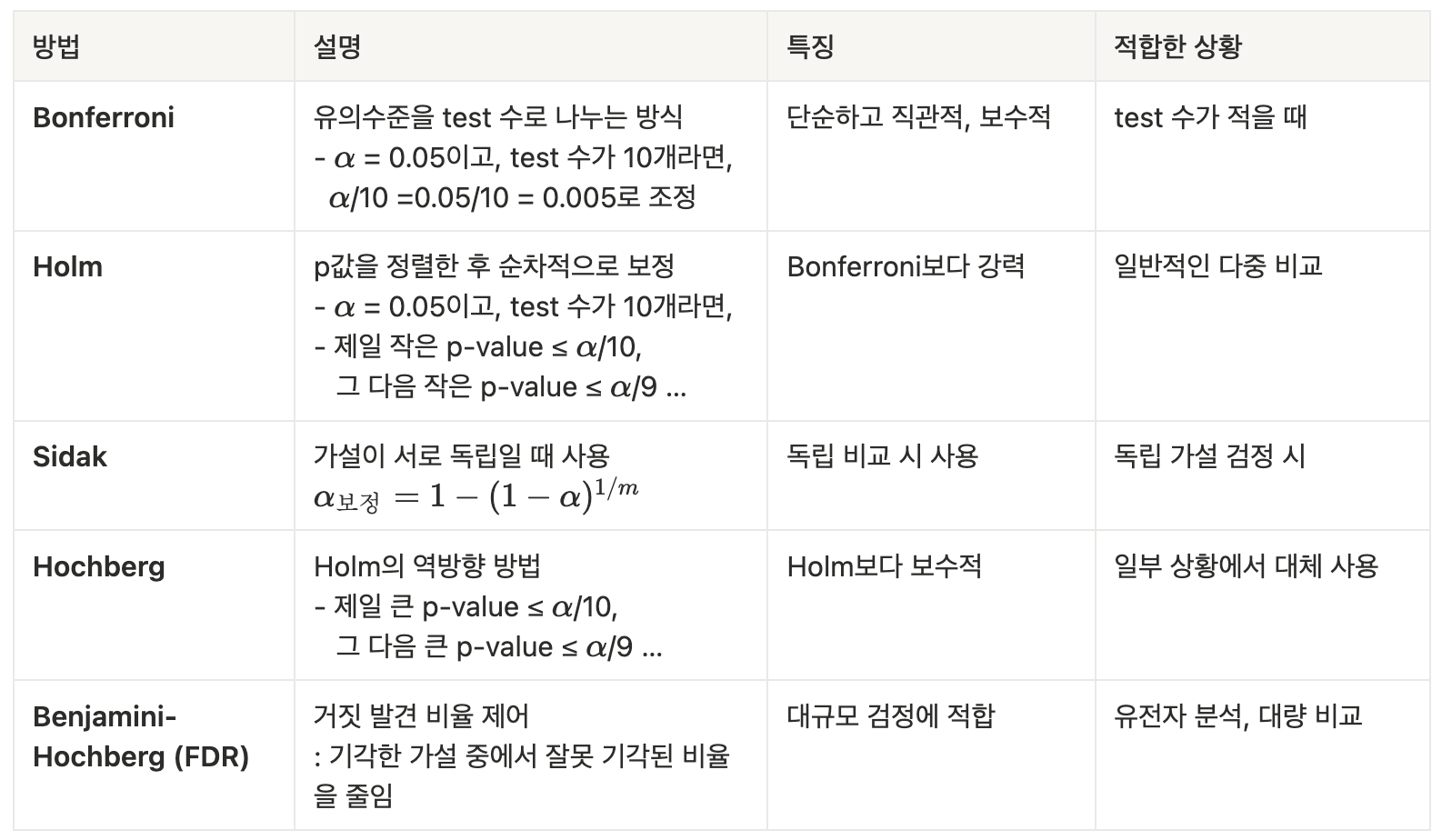
다중검정
여러 개의 가설을 동시에 검정(test) 하는 것
다중검정의 고질적 문제!?
여러 개 동시에 검정할 때, 제 1종 오류(잘못 기각할 확률)가 누적되어 전체 오류율이 커지는 현상이 발생!!
( * 제1종 오류 : 귀무가설이 참인데, 기각 )
예를들어,
10개 테스트 중 하나라도 틀릴 확률이 전체 오류율!! 그게 커진데!
언제? 여러개의 가설을 검정할 때!

이를 방지하기 위해, 아래와 같은 보정방법을 사용해서 전체 오류율을 줄임! ▼
사실 이미 눈치 챈 사람도 있겠지만 사후 검정은 다중 검정의 한 케이스로 사후 검정은 ANOVA 검정에서 차이가 있을 때 시행하는 다중검정이라고 보면 된다.
카이제곱 검정
범주형 변수를 비교할 때 사용하는 검정방법
카이제곱 적합도 검정
- 한 집단의 여러 범주 분포가 기대와 일치하는지 검정할 때 사용
- (보통 groupby 해서 수치를 뽑아보면 알 수 있기 때문에 안하게 됨 )
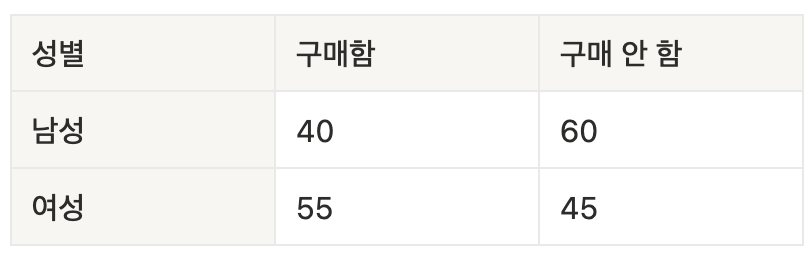
카이제곱 독립성 검정
- 두 범주형 변수 간에 관련이 있는지(독립인지)를 검정할 때 사용
- 예시
- "성별과 구매 여부가 관련이 있을까?"
- 귀무가설(H0) : "성별과 구매 여부는 서로 독립이다." (즉, 성별은 구매 여부에 영향을 주지 않는다)
상관관계
수치형 변수 일 때,
산점도 (scatter plot)
상관계수의 종류
- 피어슨 상관계수(Pearson Correlation Coefficient) : 연속형 변수
🔍 두 변수 사이 선형 관계의 정도와 방향을 수치로 표현하는 지표
scatter plot을 그려봤을 때 직선형태의 관계가 나왔을 때 사용하는 것이 적합
( 비선형인 경우, 아래의 스피어만 상관계수 또는 켄달의 타우 상관계수 사용)
- 스피어만 순위 상관계수 p (Spearman's rank correlation coefficient p) : 순위형 변수
두 변수의 순위 간 상관관계를 측정하는 지표 → 값 자체보다는 순위 차이에 집중
( 순위형 데이터이거나 연속형 데이터가 비선형일 때 사용 )
예를들어, 순위형 변수 → "만족도"
- 켄달의 타우
두 변수 간의 순위 일치 정도를 측정하는 지표 → 즉, 관측치 쌍 간의 순서가 서로 일치하는지, 불일치하는지를 비교하여 계산
( 순위형 데이터이거나 연속형 데이터가 비선형일 때 사용 )
상관계수 해석
- 세 지표 모두 -1 ≤ r ≤ 1 범위를 갖게 됨
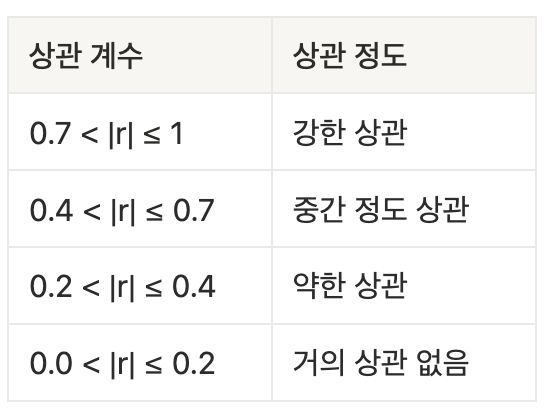
범주형 변수일 때,
- Cramer's V
범주형 변수 간의 연관성 정도를 측정하는 지표
범주형 변수의 교차표를 기반으로 (contingency table) 계산카이제곱 독립성 검정은 범주형 변수의 독립성 유무를 확인하는 거라면,
Cramer's V는 독립적이지 않은 두 범주형 변수의 상관관계 정도를 확인

끝.
'통계 (Statistics)' 카테고리의 다른 글
| [통계/인강] 챕터5 - 피어슨/스피어만/켄달타우 상관계수 | 상호정보 상관계수 (0) | 2025.10.01 |
|---|---|
| [통계/인강] 챕터4 - 선형회귀 | 다중회귀 | 범주형 변수 | 다항회귀 & 스플라인 회귀 (0) | 2025.10.01 |
| [통계/인강] 챕터3 - 유의성 검정(A/B 테스트) | 가설검정 | t-검정 | 다중검정 | 카이제곱검정 | 제 1종 오류와 제 2종 오류 (0) | 2025.09.29 |