

가장 많이 활용되는 것 위주로 학습 예정! 익숙해지 때까지 반복/응용할 것
JOIN을 하는 방법!!?
1. 공통컬럼 찾기
- 공통컬명이 꼭 같진 않을 수도 있다.
- a.id = b.user_id 처럼!
- 그래서 공통컬럼이 없으면, 조인할 수 없다.
공통컬럼이 1개인 경우
-- 모든 컬럼을 다 가져올 때
-- 테이블 구조와 데이터를 한 번에 다 확인 가능하지만 불필요한 컬럼이 포함될 수 있음.
SELECT *
FROM 테이블 AS a
JOIN 테이블 AS b
ON a.공통컬럼 = b.공통컬럼;
-- 필요한 컬럼을 지정해서 추출할 때
-- 성능 좋음, 가독성 높음, 불필요한 데이터 줄임
SELECT
a.컬럼1,
b.컬럼2
FROM 테이블 AS a
JOIN 테이블 AS b -- JOIN 종류: INNER, LEFT, RIGHT 등 지정
ON a.공통컬럼 = b.공통컬럼;공통컬럼이 2개인 경우 → AND를 붙여주면 된다!
-- 모든 컬럼을 다 가져올 때
-- 테이블 구조와 데이터를 한 번에 다 확인 가능하지만 불필요한 컬럼이 포함될 수 있음.
SELECT *
FROM 테이블 AS a
JOIN 테이블 AS b -- JOIN 종류: INNER, LEFT, RIGHT 등 지정
ON a.공통컬럼1 = b.공통컬럼1
AND a.공통컬럼2 = b.공통컬럼2;
-- 필요한 컬럼을 지정해서 추출할 때
-- 성능 좋음, 가독성 높음, 불필요한 데이터 줄임
SELECT
a.컬럼1,
b.컬럼2
FROM 테이블 AS a
JOIN 테이블 AS b -- JOIN 종류: INNER, LEFT, RIGHT 등 지정
ON a.공통컬럼1 = b.공통컬럼1
AND a.공통컬럼2 = b.공통컬럼2;
2. 공통컬럼 관계찾기 : PK와 FK 찾기
pk, fk는 다른 테이블과 연결하기 위한 "고리"같은 역할
어떤 JOIN 방식을 써야 하는지는 "우리가 보고 싶은 결과가 무엇인가?" 즉 분석목적에 따라 결정!!
3. 적절한 조인 방식찾기
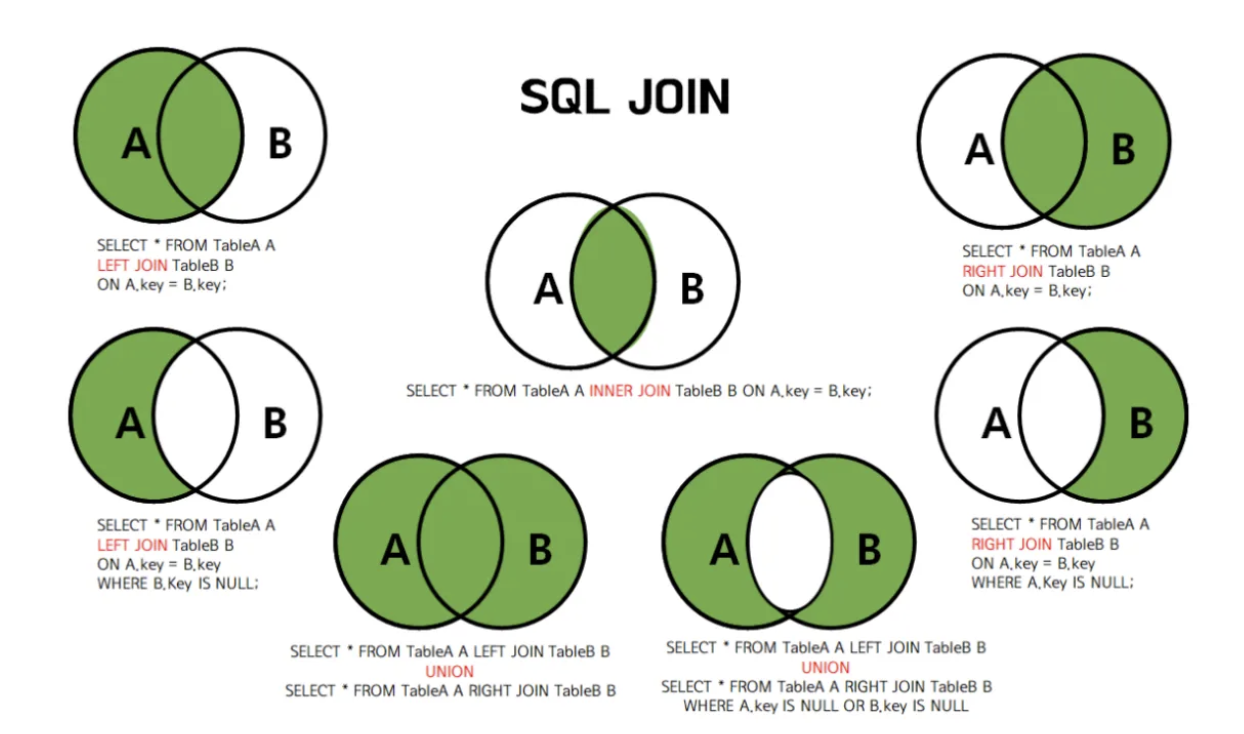
📌 INNER JOIN / LEFT JOIN이 가장 많이 사용된다!
inner join
SELECT
a.컬럼1,
b.컬럼2 ...
FROM 테이블명1 AS a
INNER JOIN 테이블명2 AS b
ON a.공통컬럼 = b.공통컬럼;left join
SELECT -- 모든 컬럼을 다 가져올 때는 * 처리 / 컬럼명에는 별칭.컬럼명 이런식으로 해주셔야해요.
a.컬럼1,
b.컬럼2,
...
FROM
테이블1 AS a -- 기준 테이블 (왼쪽)
LEFT JOIN
테이블2 AS b -- 조인할 테이블 (오른쪽)
ON a.공통컬럼 = b.공통컬럼 -- 조인 조건
---------------------------------------------------------------
SELECT -- 모든 컬럼을 다 가져올 때는 * 처리 / 컬럼명에는 별칭.컬럼명 이런식으로 해주셔야해요.
a.컬럼1,
b.컬럼2,
...
FROM 테이블1 AS a -- 기준 테이블 (왼쪽)
LEFT JOIN 테이블2 AS b -- 조인할 테이블 (오른쪽)
ON a.공통컬럼 = b.공통컬럼 -- 조인 조건📌 기준 테이블 → 테이블 1
모든 행을 포함해야 하는 테이블을 LEFT 테이블(기준테이블)로 잡는다!
➡️ LEFT에 위치한 (기준이 되는) 테이블1은 조인 조건을 만족해도 or 만족하지 못해도 모두 출력됩니다.
➡️ RIGHT에 위치한 테이블2은 조인 조건을 만족하는 경우 출력되며, 만족하지 못할 경우 NULL 값으로 출력됩니다.
WITH 구문 (CTE)
📌 하나의 테이블이 여러번 필요할 때 사용
| 구분 | 상세 |
| 정의 | SQL 구문에서 사용되는 임시 테이블(가상 테이블) |
| 사용 이유 | 쿼리의 가독성 향상 및 쿼리 성능 최적화 |
| 특징 & 장점 | - 임시 테이블처럼 사용되며, 작성한 쿼리 내에서만 유효 - 여러 개의 WITH 문 선언 가능 - 한 테이블을 여러 번 조회해야 하는 경우, 1회만 조회해 성능 향상 (한 번만 저장해놓으면 계속 쓸 수 있음) - 복잡한 JOIN, UNION 등 연산을 효율적으로 처리 |
WITH 구문 기본 작성법
WITH 임시테이블명 AS ( -- ➡️ 임시테이블명은 누구나 알기 쉬운 것으로!!
SELECT 컬럼1, 컬럼2, ...
FROM 원본테이블명
WHERE 조건
)
SELECT 원하는컬럼1, 원하는컬럼2, ...
FROM 임시테이블명;조금 복잡한 구조는?
WITH 임시테이블명 AS (
SELECT
컬럼1,
컬럼2,
집계함수(컬럼3) AS 집계값,
윈도우함수() OVER (
PARTITION BY 컬럼1
ORDER BY 컬럼2
) AS 윈도우값
FROM 원본테이블명
WHERE 조건식
GROUP BY 컬럼1, 컬럼2
HAVING 집계조건식
)
SELECT
원하는컬럼1,
원하는컬럼2,
...
FROM 임시테이블명
ORDER BY 정렬기준컬럼 ASC;✅ WITH 구문 예시 중 다중 WITH 구문
-- 첫 번째 임시 테이블 gogo 정의: 레벨 50 초과 유저
WITH gogo AS (
SELECT
game_account_id,
exp
FROM
basic.users
WHERE
`level` > 50
),
-- 두 번째 임시 테이블 hoho 정의: 카드 결제 정보
hoho AS (
SELECT DISTINCT
game_account_id,
pay_amount,
approved_at
FROM
basic.payment
WHERE
pay_type = 'CARD'
)
-- 결제 여부별 유저 수 집계
SELECT
CASE
WHEN b.game_account_id IS NULL THEN '결제x'
ELSE '결제o'
END AS gb,
COUNT(DISTINCT a.game_account_id) AS accnt
FROM
gogo AS a
LEFT JOIN
hoho AS b
ON
a.game_account_id = b.game_account_id
GROUP BY
CASE
WHEN b.game_account_id IS NULL THEN '결제x'
ELSE '결제o'
END;🚨 주의할 점 : 맨 위에 한 번만 선언
여러 개의 CTE가 필요하다면 아래처럼 콤마( , )로 연결
✅ 서브쿼리 vs WITH 문 (공통 테이블 표현식)
| 항목 | 서브쿼리 | WITH 문(CTE) |
| 위치 | SELECT, FROM, WHERE 절 안에 바로 씀 | 쿼리의 맨 위에 작성 |
| 재사용 | 안됨 | 여러 번 참조 가능 |
| 가독성 | 복잡해지기 쉬움 | 가독성이 좋고 유지보수에 유리 |
| 사용 예 | 간단한 조건에 자주 사용 | 복잡한 로직 처리 시 선호 |
| 상황 | 추천 도구 | 이유 |
| 쿼리가 길고, 중간 계산을 나눠서 작성하고 싶을 때 | WITH 문 | 각 단계를 이름 붙여 관리 가능, 가독성↑ |
| 같은 쿼리를 여러 번 써야 할 때 | WITH 문 | 중복 제거, 재사용성↑ |
| 쿼리가 짧고 단순한 조건만 필요할 때 | 서브쿼리 | 간결하게 처리, 오히려 WITH보다 짧고 명확 |
| 성능 최적화가 중요할 때 | 상황에 따라 다름 | 어떤 RDBMS에서는 서브쿼리가 더 빠를 수도 있음 (즉, DB 엔진마다 다름) |
▼ WITH 구문(CTE)를 써야하는 대표적인 상황
더보기
1. 같은 서브쿼리를 여러번 재사용 할 때
- 같은 집계 결과를 여러번 사용하라.
- 먼저 ~의 합계를 구한 후, 이를 이용해서 … 계산하라.
- 예시
WITH SalesSummary AS (
SELECT customer_id, SUM(amount) AS total
FROM sales
GROUP BY customer_id
)
SELECT *
FROM SalesSummary
WHERE total > 1000;
2. 문제를 단계별로 쪼개야 할 때
- 먼저 A를 구한 뒤, 그 결과를 이용해서 B를 구하라
- 중간 결과를 바탕으로 최종 결과를 출력하라
- 즉, 중간 단계 → 최종 답 구조가 나오면 WITH가 잘 맞음
3. 가독성을 높이고 싶을 때
- 문제에 복잡한 조건이나 중첩 서브쿼리가 나오면, CTE로 나누면 보기 편해집니다.
- 예시) 평균 이상을 구하고, 그 결과를 다시 집계 같은 문제 → 이런 경우에는 서브쿼리도 좋지만 CTE로 이름 붙여도 괜찮은 풀이가 될 수 있음.
- 서브쿼리 버전
SELECT e.dept_id,
COUNT(*) AS cnt_above_avg
FROM employees e
WHERE e.salary >= (
SELECT AVG(salary)
FROM employees
WHERE dept_id = e.dept_id
)
GROUP BY e.dept_id;- CTE 버전
WITH dept_avg AS (
SELECT dept_id, AVG(salary) AS avg_salary
FROM employees
GROUP BY dept_id
),
above_avg AS (
SELECT e.dept_id, e.emp_id, e.salary
FROM employees e
JOIN dept_avg d ON e.dept_id = d.dept_id
WHERE e.salary >= d.avg_salary
)
SELECT dept_id,
COUNT(*) AS cnt_above_avg
FROM above_avg
GROUP BY dept_id;✅ 실무에서는? 상황에 맞게 선택해서 사용
복잡한 로직이면 WITH 문 선호 (가독성, 유지보수 측면)
단순 조건만 있는 경우엔 서브쿼리도 많이 사용
SQL 문제 풀이의 핵심 키워드 유형
➡️ SELECT 절 관련 키워드
| 키워드 | 의미 | 예시 |
| 가장 큰, 최고, 최대 | MAX() 사용 | 가장 큰 점수를 가진 학생 |
| 가장 작은, 최소 | MIN() 사용 | 최소 급여를 받는 직원 |
| 평균, 평균값 | AVG() 사용 | 평균 나이 이상인 회원 |
| 합계, 총 | SUM() 사용 | 총 매출이 100만 이상인 지점 |
➡️ WHERE 절 관련 키워드
| 키워드 | 의미 | 예시 |
| ~한 사람, 조건을 만족하는, ~이 아닌 | WHERE 조건문 필요 | 나이가 30 이상인 고객 |
| ~을 포함, 포함된, ~중 하나 | IN, LIKE | '서울', '부산' 거주자 |
| ~가 아닌, 제외하고 | NOT, !=, NOT IN | 관리자 제외 |
➡️ JOIN 관련 키워드
| 키워드 | 의미 | 예시 |
| ~에 속한, ~의, ~정보와 함께 | 두 개 이상의 테이블 연결 필요 | 주문 정보 + 고객 정보 |
| 같은, 일치하는 | ON 조건 설정 필요 | 같은 부서의 직원 |
➡️ GROUP BY 관련 키워드
| 키워드 | 의미 | 예시 |
| ~별로, 각, ~당 | GROUP BY | 부서별 평균 급여 |
| 가장 많이, 가장 적게 | GROUP BY + COUNT() + ORDER BY DESC | 가장 주문이 많은 제품 |
➡️ ORDER BY 관련 키워드
| 키워드 | 의미 | 예시 |
| 정렬, 순서, 내림차순, 오름차순 | 전체 결과를 정렬 | 점수 높은 순 정렬 |
➡️ HAVING 절 관련 키워드
| 키워드 | 의미 | 예시 |
| 집계 결과 조건, ~이상인 그룹, ~이하인 그룹 | 그룹화된 결과에 조건 적용 | 주문 수가 10건 이상인 고객 |
➡️ DISTINCT 관련 키워드
| 키워드 | 의미 | 예시 |
| 중복 제거, 고유한, 유일한 | 중복 데이터 제거 | DISTINCT 도시 개수 |
➡️ LIMIT / TOP 관련 키워드
| 키워드 | 의미 | 예시 |
| 상위, 하위, 몇 개만 | 조회 결과 개수 제한 | 급여 상위 5명 |
➡️ CASE / 조건식 관련 키워드
| 키워드 | 의미 | 예시 |
| 조건에 따라, 분류, 구간 | 조건별로 다른 값 출력 | 점수에 따라 합격/불합격 표시 |
➡️ 서브쿼리 관련 키워드
| 키워드 | 의미 | 예시 |
| ~의 결과를 이용해, ~에서 뽑은 값으로 | 쿼리 안의 쿼리 사용 | 평균 급여보다 높은 직원 조회 |
➡️ 윈도우 함수
| 키워드 | 의미 | 예시 |
| 순위, 누적, 이전 값과 비교 | 그룹 내 순위, 누적 합계 계산 | 지점별 매출 순위 (RANK()) |
문제가 어렵고, 어디서부터 손대야 할지 모르겠어...🤷♂️
1. 문제를 2-3개의 질문으로 쪼개기
- 통과한 사람의 평균 점수?
- 통과 기준은?
- 점수는 어디 컬럼?
- 평균은 group by가 필요하나?
2. SELECT부터 적기 → FROM → WHERE → GROUP BY → HAVING → ORDER BY
3. SELECT * 로 해보고 데이터부터 보는 연습!
4. SQL 작성 전 체크리스트
- 문제 정의 : 의도가 무엇인가?
- 요청사항을 정확히 아는 것
- 문제의 요지 분석
- 예상 쿼리를 구성(GROUP BY 써? SUM() 써?
5. 데이터 구조 확인 (테이블의 컬럼명 확인)
문제1
문제2
문제3
https://teamsparta.notion.site/SQL-2-2722dc3ef514803f9438fa191faafc3f
[베이직반] SQL 2회차 | Notion
[ 강의 자료 ]
teamsparta.notion.site
'SQL' 카테고리의 다른 글
| [SQL/코드카타] 프로그래머스 - 특정 기간동안 대여 가능한 자동차들의 대여비용 구하기 (NOT EXISTS) (1) | 2025.09.30 |
|---|---|
| [SQL/QCC] 실전 연습 2차 - 코딩 테스트 2문제 (0) | 2025.09.26 |
| [SQL/코드카타] 프로그래머스 - 조건에 부합하는 중고거래 댓글 조회 (DATE, DATE_FORMAT, USING, WHERE) (0) | 2025.09.26 |